Designing Better In-Protocol Authority Structures
Robert Reith · Apr 7, 2026 · 12 min read
Designing Better In-Protocol Authority Structures
The Drift hack worked because multiple components enabled it. A weak 2/5 multisig with no timeouts. Blind signing on hardware wallets. Durable nonces allowing execution of asynchronously signed transactions at once. A slow response. But also, an overpowered single admin authority allowed to edit security limits, add assets, and instantly change the admin key.
The two authority planes
On Solana there are two distinct authority planes. First, there is the upgrade authority: this account can deploy new versions of the code to an existing address. Revoking this authority makes a program immutable.
Second, there are privileged instructions your program exposes in its own state machine. List assets, delist assets, change risk params, switch oracle settings, take fees, change fee settings, pause markets, rotate admins, and so on.
Those are radically different powers with radically different failure modes, so they should almost never be controlled in the same way.
In this post, we want to address the in-protocol authority plane. Drift used a single configured in-protocol admin authority which was able to do most administration tasks. This is a simple design, and frankly quite common. However, while simplicity is often good for security, in this case it was a big problem. The attacker was able to hijack this one admin with just one instruction: transferring the authority to the attacker. Next, they were able to add a new asset, adjust security limits, and then drain the protocol.
Now you might have already guessed the obvious fix for that. We could separate administration functions and assign them to different authorities according to their risk profile, while also enforcing timeouts as security controls. That's the simple core idea, and we want to discuss how to do this. Whether you are designing a new protocol or auditing an existing one, this framework gives you a systematic way to evaluate and structure admin authority.
The first step is to enumerate your admin instructions and assess the risk profile of each. You can do so by asking two simple questions:
- What happens if a malicious actor can trigger this once?
- What is the fastest the protocol may need to trigger this itself?
That gives you two scores:
- Risk
- 0: catastrophic loss of funds (malicious program upgrade)
- 1: major loss of funds (similar to drift)
- 2: minor loss of funds, fees, yield, or targeted/socializable losses
- 3: loss of availability
- 4: lower than that
- Timeliness
- 0: immediate
- 1: within the hour
- 2: within the day
- 3: within the week
Now you'll enter the real design loop: make operations less timely and less risky. Scoring is only the first pass. After you score an operation, ask two more questions:
- Can I make this operation less timely?
- Can I make this operation less risky?
You repeat that loop until the easy “yes” answers mostly disappear. How do you make operations less timely or risky though?
The main way to make an operation less timely is to add a safer fallback action. If you have a way to halt the protocol, upgrades stop being an emergency response. If you can tighten oracle guard rails or disable a market, an oracle-source migration stops being a hot-path action.
The main way to make an operation less risky is to constrain the operation itself. Turn "set fee" into "set fee within a hard-coded range." A deposit fee probably should never be more than 10%, and even that is high. So don't just check that the fee parameter is a valid BPS value, but make sure it's in within reasonable bounds! Turn "collect fees" into "sweep from a dedicated revenue pool to a fixed treasury." Fee collection is a great example of how implementation changes classification: if the sweep authority can touch user collateral, it is basically a treasury drain authority in disguise. If fees are segregated into dedicated pools, the same power becomes much lower risk.
Another good way to reduce risk is to separate instructions into their risk-reducing and their risk-increasing parts. Turn "change maximum oracle staleness" into separate "tighten" and "loosen" instructions.
A good rule of thumb is this:
Every privileged action should be either slow or one-way.
If it is fast, it should only be able to reduce risk.
If it can move value, expand risk, or re-enable the system, it should be slow.
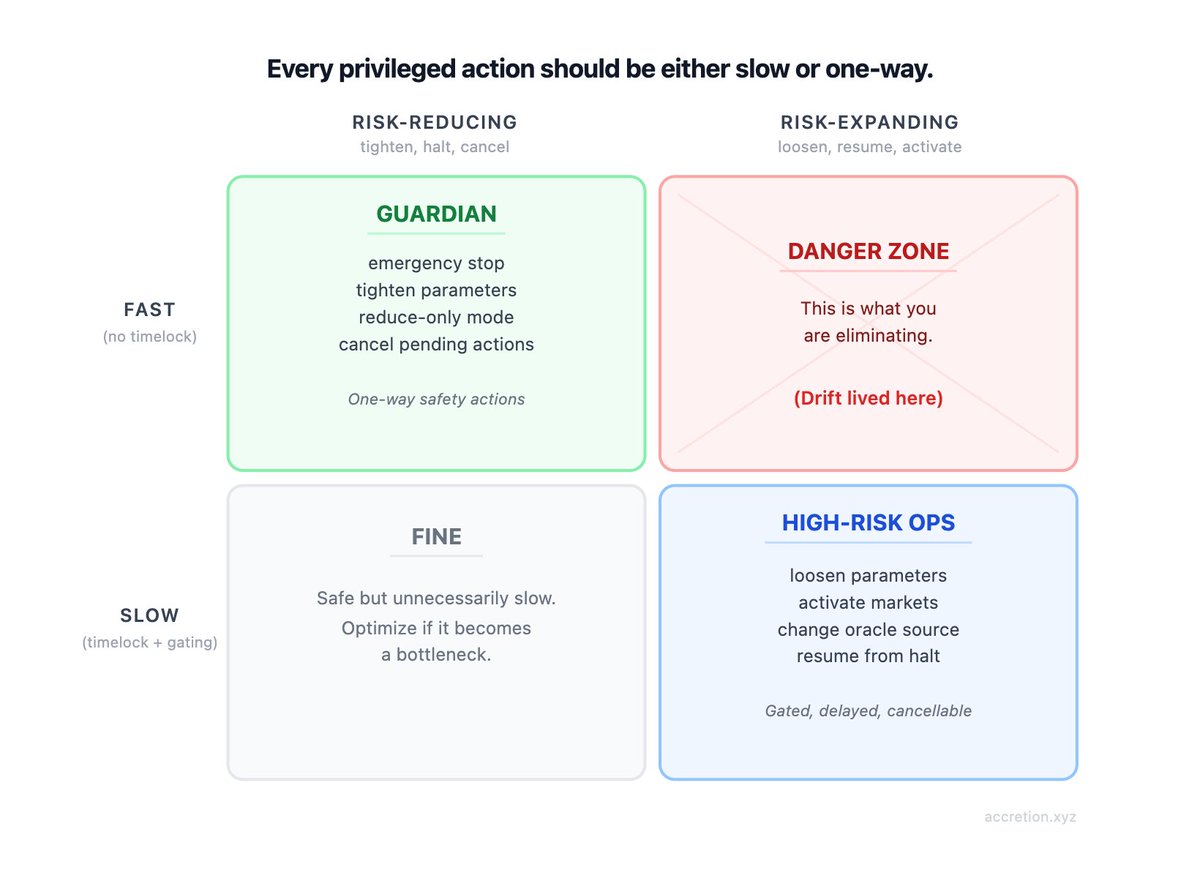
A practical example matrix
After splitting the broad buckets, a baseline matrix grouped by authority level looks like this:
Vault level
| Operation | Risk | Timeliness | Notes |
|---|---|---|---|
| Upgrade code | 0 | 2 | Full code replacement |
High-risk ops (slow, gated, cancellable)
| Operation | Risk | Timeliness | Notes |
|---|---|---|---|
| Resume / unhalt / widen whitelist | 1 | 2 | Can reopen exploit surface; may require vault |
| Activate market / enable collateral, borrowing, leverage | 1 | 3 | Bad config can create insolvency |
| Loosen risk parameters | 1 | 3 | Expands the risk envelope |
| Change oracle source / relax oracle checks | 1 | 2 | Incorrect repricing risk |
| Change fee recipient or fee bounds | 1 | 3 | Can redirect value or remove safety rails |
| Final delist / settle expired market | 2 | 2 | Value-moving, but not emergency if reduce-only exists |
| Create market in disabled / isolated state | 4 | 3 | Safe if not yet usable |
Low-risk ops (bounded downside)
| Operation | Risk | Timeliness | Notes |
|---|---|---|---|
| Sweep fees to fixed treasury | 2 | 3 | Assumes fees are segregated |
| Change fee parameters within hard bounds | 2 | 2 | Economic harm, but bounded |
Timely guardian (fast, risk-reducing only)
| Operation | Risk | Timeliness | Notes |
|---|---|---|---|
| Emergency stop / fund-flow stop | 3 | 0 | Availability hit only, if designed well |
| Enter reduce-only / start delisting | 3 | 1 | Caps further exposure |
| Tighten risk parameters | 3 | 1 | Safer direction, but can disrupt users |
| Tighten oracle guard rails / disable market | 3 | 1 | Prefer halt over trusting bad data |
Cancellation guardian
| Operation | Risk | Timeliness | Notes |
|---|---|---|---|
| Cancel/remove pending or compromised admin | 3 | 0 | Emergency containment |
Admin transfers (cross-level)
| Operation | Risk | Timeliness | Notes | Authority |
|---|---|---|---|---|
| Propose admin transfer | 4 | 3 | No effect until accepted | Same level or higher |
| Accept admin transfer | inherits target role | 2 | Should be delayed and cancellable | Target role, post-timeout |
The most important thing in these tables is not the exact numbers. It is the shape. Dangerous and permissive actions drift upward into slow, highly trusted authorities. Fast authorities mostly disappear into narrow, one-way safety actions.
A base authority structure that works for most protocols
For most Solana protocols, a sane default is five layers.
1. Vault level
This is the coldest, slowest, most trusted authority. It should own the program upgrade authority and any truly existential meta-powers. Highest threshold. Longest timeout. Cold signing environment. Separate laptops. This is the role you lock down hardest. For practical multisig sizing guidance, see Tips #22-23 in our 100 Solana tips.
One more practical point: the upgrade authority is above every in-protocol admin. Even if your program has its own admin tree, the upgrade authority can always ship new code that changes it. Treat that as a break-glass layer, not just another peer role.
2. High-risk operational level
This is for dangerous but non-existential state changes: activating new markets, loosening risk parameters, switching oracle sources, relaxing checks, final delisting settlement, changing fee recipients, accepting high-privilege admin transfers, and resuming from emergency states.
This level should still be slow. It can have a shorter timeout than vault-level upgrades, but it should remain heavily gated and cancellable.
3. Low-risk operational level
This is for routine operations with bounded downside: sweeping fees from dedicated revenue pools to a fixed treasury, bounded fee changes, and other housekeeping actions that do not touch user solvency or protocol control.
If a “low-risk” authority can change an oracle, change a recipient, or re-enable the system, it is not actually low-risk.
4. Timely guardian level
This is the fast path. It should have no timelock and a much lower coordination burden, but the tradeoff is strict scope: it should only be able to make the protocol safer.
That usually means powers like:
- trigger emergency stop
- stop fund flows
- put a market into reduce-only
- tighten risk limits
- tighten oracle guard rails
- cancel pending queued actions
It should not be able to resume the protocol, loosen limits, switch oracle sources, move treasury funds, or rotate admins into power.
This level should usually be split in two:
- a manual guardian multisig for human-triggered emergency intervention
- a very narrow automation hot wallet for deterministic stop actions
The automation wallet should be treated as a brake pedal, not a steering wheel. It is fine to let a hot key halt a market or stop fund flows based on predeclared conditions. It is not fine to let that same hot key decide a new oracle source or increase risk parameters.
5. Cancellation guardian
This role exists to interrupt queued or pending dangerous actions during their timeout window. It is especially valuable for admin transfers and other delayed high-risk operations. In some systems this can be the same signers as the manual guardian. In others it can be even broader, because veto power is often safer to distribute than execution power.
The ideal cancellation guardian can stop bad things without being able to do many positive things itself.

On circuit breakers
One core function that every protocol should have is a circuit breaker or global program state. This state is checked at the entrypoint and can disallow any further action. The main circuit breaker states we recommend are just Normal operation and Emergency stop until upgrade, but you can also add intermediate states that restrict the protocol to a subset of operations.
The key property is monotonicity: fast authorities can only increase restrictions, while only slower, more trusted authorities can relax them back toward normal operation.
That leads to a practical answer to a subtle question: what should be allowed while halted?
The answer is not “all admin ops.” It should be a very small recovery plane:
- stricter emergency transitions
- cancel/remove admin operations
- code upgrade / recovery path (which is open anyways)
- possibly very specific settlement instructions if they are explicitly whitelisted and known-safe
However, when a hack is happening, you don't immediately know the root cause of the bug. Halting the protocol while still allowing some instructions always retains the risk that those specific instructions are directly vulnerable or indirectly affected in some way.
Even a "safe" settlement instruction can become net-negative if it calculates its actions on internal accounting which was already broken by a bug elsewhere. That's why the safest default is just to halt all operations until a program upgrade.
Safe Admin Transfers
Transferring administrator rights is one of the most sensitive operations a protocol can perform. A compromised transfer mechanism is exactly how the Drift attacker took control. The safe pattern is a two-step process with a cancellation window:
- The current admin proposes a new admin address
- A mandatory timeout window begins
- After the timeout, the new admin accepts the role
- During the timeout, the cancellation guardian or the current admin can cancel the proposal
- Separately, a higher authority or the cancellation guardian can instantly remove a compromised admin without going through the proposal flow
The core principle: adding power should be slow, removing power should be fast.
If an admin compromise is suspected, the choreography should be obvious:
- guardian halts or tightens the protocol
- cancellation guardian cancels any pending malicious changes
- stronger authority removes or rotates the compromised admin
- resume only after review, not by the same fast role that triggered the stop
The design principle underneath all of this
Most protocols need administrative actions to operate.
The goal is to make sure each privileged action has the smallest possible blast radius and the largest possible response window.
That means:
- split broad actions into directional, phased, and scoped actions
- add bounded-value invariants wherever possible
- add safer fallback operations so dangerous actions are less urgent
- keep fast powers one-way
- keep permissive powers slow
- separate stop from resume
- separate tighten from loosen
- separate propose from accept
- keep upgrade authority above and apart from routine admin
If you do that repeatedly, the authority structure starts to clarify on its own.
The wrong question is, “Which multisig should own admin?”
The right question is, "What is the smallest power that solves this problem at the speed we need?"
That question is what turns a vague "admin system" into an actual Solana authority architecture.
If you're designing or reviewing an authority structure, an audit helps validate your design.
Accretion Labs Pte. Ltd.
65 Chulia Street, #46-00 OCBC Centre
Singapore 049513
Singapore
UEN 202502288W