r0bre's 100 daily Solana tips
Robert Reith · Jun 10, 2025 · 88 min read
r0bre's 100 Daily Solana Tips
Earlier this year, over the course of 3+ months, I wrote 100 Solana tips, releasing one every single day. During that time I have received many requests for a long form Blogpost where all the tips are listed together — here it is. Enjoy!
(Original thread on X) https://x.com/r0bre/status/1878796569597882757
Daily Solana Tip 1
Structure your project. If your whole code lives in a single
lib.rs
file, it becomes hard to work with. (At the latest when a second person looks at your code). Split it up.
The structure I propose:
-
lib.rs
-
instructions/
-
init.rs
-
transfer.rs
-
-
state/
- global.rs
-
lib.rs
Your lib.rs should just contain code to call the instruction handlers.
each instruction file, such as init.rs, shall contain the Accounts struct, validation functions, and the business logic / implementation of this instruction.
Each state file, such as global.rs, shall contain an account definition, including implementations for that specific state account.
This will make it much easier for everyone working with your code.
Anchor even has a built in command to generate your repository with this structure:
anchor init <NAME> --template multiple
Daily Solana Tip 2
When writing Anchor constraints, try only using has_one. When has_one isn't possible, and the constraint is more complex than a simple key comparison, put it into a separate validation function instead. And add custom error codes in your constraints. For more on Anchor's internal workings, see our article on hidden IDL instructions.
Daily Solana Tip 3
Don't know how to write good Solana programs? Go and see how well-built dapps have done it. I recommend studying @SquadsProtocol v4 for the basics. https://github.com/Squads-Protocol/v4
For great non-Anchor code, read @sanctumso's S, and Ellipsis Labs’ Plasma/gavel
Daily Solana Tip 4
Blockchains have a wonderful mechanism: You can process a whole Transaction, generating a theoretical state transition S->S', and then roll it back if S' looks fishy. To do this, you can use invariants.
Invariant functions are defined on state. They check if the given state is valid, and return an error if not.
You can call them at the end of an instruction that changes the state, to make sure that the new state will be valid. The following example is from Squads v4.
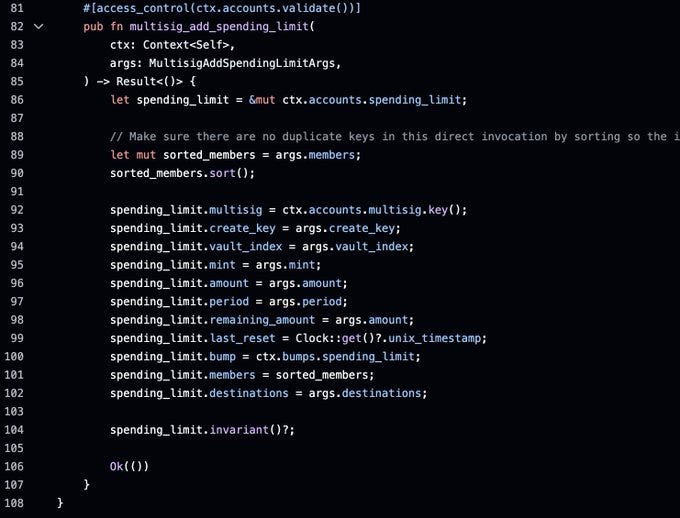
As you can see the invariant is called at the end of the function. The shown invariant for a spending limit makes sure that the amount is never 0, and that the member list isn't empty or has duplicates.
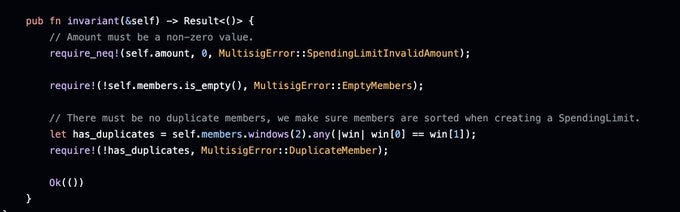
It's called an invariant because now we can make a statement that's always true / invariant: The member list of a spending limit is never empty.
Daily Solana Tip 5
Yesterday we learned about invariants. They are defined on state and are static. But we can use the same principle as dynamic assertions in our instructions.
For example, a deposit function.
When a user deposits funds into our contract, the amount of funds should increase, and never decrease, which would be a security issue.
We can build such an assertion by saving the total deposits amount at the beginning of our instruction and at the end. Then we assert that at the end, the amount is larger than at the beginning.
It's a simple yet effective technique for adding safety to your programs!
Daily Solana Tip 6
Use a global program state account with a global state enum for different Operating levels.
For example, you may want a state for normal operation, fully halted operation, withdraws only, or limited operation allowing only a subset of instructions to be called.
The state should be changeable by an admin key different from the upgrade authority. Ideally, this account can be passed as read-only to most of your instructions. For a full framework on admin authority design, see our post on designing better authority structures.
This will allow you to quickly react in case of an incident, such as a hack, a sudden bug, or even an ecosystem issue such as a stablecoin depeg.
Just imagine a hack is happening, and you can't stop it because the emergency program upgrade isn't going through. It will be much easier landing a simple state change instruction that will stop vulnerable instructions from being callable.
Daily Solana Tip 7
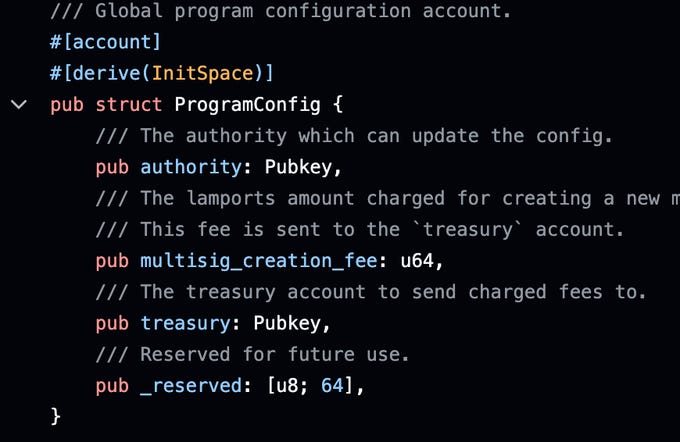
Future proof your contract by adding empty padding to your account structs. See the _reserved field in this structure? It will allow adding additional fields to this type in the future, without breaking backwards compatibility.
How much padding should you add? Well theoretically just a single byte can be enough if you use the Option<> type in the future. Because Option::None is serialized to a single 0-byte, (while Option::Some<> will be longer data), adding a single 0-byte to your structure now will allow it to be extended. If you don't want to rely on Option types (because maybe you want a static struct size), you should probably keep at least 64 bytes of padding to cover most types that may be added.
Daily Solana Tip 8
When designing the structure layouts for your program's onchain data, try putting any fixed-size values at the beginning of your structure, while putting variable-size values, such as options or vectors at the end of your structure. This will allow you to always read the fixed size values at a static offset, which can be helpful for some RPC methods that require a fixed offset
Daily Solana Tip 9
When deciding on the seeds for your PDA's, follow this simple pattern:
-
Start every seed with some static string, such as "pool"
-
Add a special character at the end of each seed prefix, e.g. "pool" -> "pool:"
-
Alternatively make sure that none of your seed prefixes is a substring of another seed prefix
-
Example: different account seeds "pool" and "pool_admin" should be avoided, because "pool_admin" starts with "pool". "pool:" and "pool_admin:" is ok though.
-
Next, use pubkeys in your seed. For example "pool:" + mint.key()
-
At the end, you can add numerical IDs if necessary
-
Avoid using variable-length strings or bytes. If you have to, put them at the very end of your seeds.
-
Overall pattern: static string + pubkey(s) + ID
-
Keep it simple. Don't add unnecessary seeds
This pattern should cover >90% of cases!
Daily Solana Tip 10
Anchor's remaining accounts are dangerous. Use them with extreme care.
These accounts are basically unchecked accounts, and are often used for CPI.
When using them, you have to manually verify these accounts, which includes owner checks, seed checks, discriminators and data. Oftentimes, devs forget to perform an owner check on these accounts, only deserializing them. Or forgetting another check. This can lead to serious vulnerabilities, and I've seen this increasingly in the past year.
So make sure to correctly check remaining accounts when using them:
-
Expected number of remaining accounts is correct
-
For each account: Always check owner and discriminator. If necessary, check PDA seeds and contents as well.
Daily Solana Tip 11
Logging using the log syscall on solana costs a lot of compute, and truncates your logs if they are too long. But performing a CPI with the same amount of data (the string you want to log) as call-data is cheap, and is not prone to truncation. That's why we have a noop program (program that does nothing), and noop instructions for self-cpi's. Using them means calling a program or instruction with your logs as an argument, and doing nothing with them. Then you can build an indexer to read these logs off-chain. Note that this may be vulnerable to log-spoofing if other programs call this endpoint or program, so it's important to have authentication in place, so the call fails when called by an outsider.
Read one of the original discussions about this here: https://github.com/coral-xyz/anchor/issues/2408
Anchors emit_cpi! macro uses exactly this pattern to create cheap event logs.
Fun fact: that's also how account compression works - large amounts of data saved in cheap call-data as opposed to expensive on-chain data.
Daily Solana Tip 12
Solana can parallelize multiple transactions because each transaction has to pre-define what accounts it will read and write. If two transactions read from the same account, they can be executed in parallel. If one writes, and the other reads, they have to be executed sequentially, otherwise we would run into consensus issues when its unclear if the read happened before, or after the write.
Explicitly, this means that solana can not parallelize instructions of your program if they both write to the same account. This becomes important when your program is called a lot -- like an AMM, a meme bonding curve, or minting contract during some event with significant volume.
In these situations, you want your contract calls to not block each other, which means that you want to reduce writes to the same account. Now what account is typically written to a lot? The best example is your fee treasury. When you collect fees on every single trade, and all fees are sent to the same account, this will create a lot of write locks on the same account, and prevent your transactions from being parallelized.
One solution is to use multiple fee treasury accounts instead of just one. This balances the write locks across them.
But how do you get each user to actually use a different fee treasury?
@tensor_hq came up with the clever idea of using the last byte of another Pubkey in an instruction as the shard identifier. The byte can be anything between 0 and 255, so we will have 256 different fee treasuries.
If the pubkey we derive the shard from is sufficiently different from transaction to transaction, then we will effectively distribute the write locks between 256 accounts.
The only drawback is that the admin will need a script to collect the fees from these 256 accounts, but that shouldn't be a problem.
Fee treasuries aren't the only accounts being write-locked a lot. Next time you're coding, take a look at your program and see what write locks could become problematic, and see if you can distribute them.

Daily Solan 13
One programming mistake even rust can't save you from is mathematical errors. This includes mistakes where you're just bad at math, but also mistakes where the computing environment creates unexpected (to the programmer) behavior, such as overflows or underflows. What happens if you subtract 1 from 0_u8? Unsigned bytes don't have negative numbers, they're unsigned. The result is 255. In the context of financial applications, this is quite scary. Deduct 1 token from my account, and now I'm rich? Good for one user, not good for the protocol. Rust gives you tools to protect yourself:
safe math. Functions like checked_add, saturating_add, etc. allow you to handle such edge cases safely. As a rule of thumb: Never use +, -, or * operators directly, and use their safe versions instead when doing financial math. Use them only if you can mathematically prove (ideally in a comment next to your code) that overflows or underflows will never occur. For a detailed breakdown of the compute costs of checked vs unchecked math, see our cost of security analysis.
Daily Solana Tip 14
The mainstream media might have told you that there is no reentrancy on Solana. Don't believe their lies. There exists a special class of reentrancy, and often is a source of security vulnerabilities: Self-reentrancy.
What is it? A normal reentrancy typically involves two contracts. The first, vulnerable contract transfers funds to another contract, which is an attacker contract. The attacker contract executes a recipient hook function and calls back into the vulnerable contract. The vulnerable contract now is re-entered while in the middle of a transfer, a transitory state, which leads to vulnerabilities.
Solana forbids this pattern: A -> B -> A
B is not allowed to call A after it already exists in the call stack.
But on Solana, there is an important exception: Self-reentrancy. A -> A calls are allowed.
Now this can only be a problem if an attacker could control such a call, and turn it into something unexpected. For example, a contract A that allows you to call any other contract B. An attacker could try to instruct A to call not just any other contract, but instead call itself.
What kind of contract works like this? Actually quite a few! For example, Multisigs, or DAOs.
In a MS or DAO, users create proposals to call another contract with some arguments. For example, call the token program for a token transfer, or raydium for a swap.
A badly built MS or DAO program could be vulnerable to self reentrancy, where a user creates a proposal which calls the Multisig itself to relinquish a vote.
Once the proposal is executed, the execution will call the multisig program, see the executable proposal, relinquish a vote on it, turning it non-executable. After this, execution is finished and the proposal is executed. Or non-executable??
Well, the proposal is in a weird state that shouldn't really have happened.
These kinds of self-reentrancy bugs can occur in any program that invokes a user-chosen program. Often its best to prevent them by explicitly forbidding self reentrancy calls by checking the program address before calling it.
Sometimes its enough to ensure the CPI does not write to any account owned by our program itself.
Most importantly, you should know that this pattern exists. If you're a dev, it might save you from a bug. And if you're an auditor, this might be your next finding ;)
Self Promo time: Thanks for reading two weeks of my daily posts. I enjoy writing them and will keep doing so. If you're building on Solana and are looking for a security audit, DM me. Accretion's mission is to provide the best Solana audits while making it easy to get audited. Curious about pricing? See our breakdown of how much a Solana audit costs.
Daily Solana Tip 15
I see this extremely simple, but often serious bug in every second audit. Can you spot it?
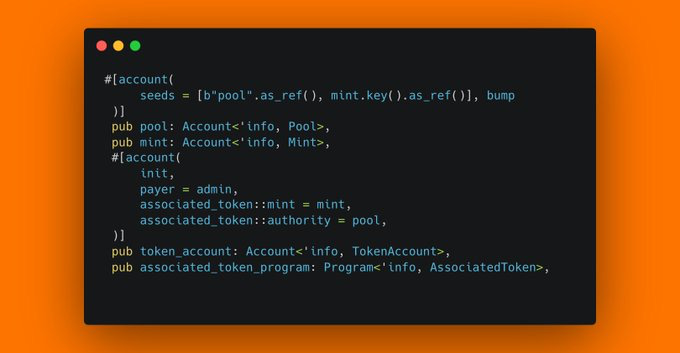
If you caught it, pat yourself on the back. If not, well it's quite simle: Never just init Associated Token Accounts. init_if_needed them instead.
Why? Anchors init constraint will fail when an account already exists. And anyone can create an ATA account for any authority, that's their whole point.
In this case, an attacker could create the ATA for this pool and mint before this instruction is called. After the ATA is created, this instruction is uncallable as init will always fail. Sometimes the bug isn't so serious when they can just use a different authority and achieve the same goal in your protocol. But often, there can only be one pool for one specific mint, because it's seeded through the mint's key. And therefore even when the pool doesn't even exist yet, we could create the ATA account for the pool for a specific mint - and effectively DoS your protocol from using a specific mint in its pools.
To summarize: an attacker can effectively DoS your protocol by creating token accounts for your protocol. Funny how that works.
So remember: ATA auth is seeded? use init_if_needed
(And also, audit is needed? Dm me bro)
Daily Solana Tip 16
There have already been great threads and docs on this, so I'll keep this short.
When your instructions take an authority account as a Signer input, and need to pay fees for account creations or reallocations, it may be smart to add a separate Signer who will act as the payer on the transaction. Users can still choose to pay the fees using the same authority by passing it for both payer and authority, but they gain the option of paying from a different account. This improves your program's ecosystem interoperability because when other programs act as authorities through the PDA mechanism, they might not have adequate funds on the PDA accounts itself.
Note that users can always indicate a separate fee payer for transaction fees, so this primarily applies to fees related to rent, or protocol fees.
Here are some further resources on this:
https://developers.metaplex.com/guides/general/payer-authority-pattern
https://x.com/blockiosaurus/status/1874868866716950831
Daily Solana Tip 17
When writing your program it's a great habit to write many custom error codes, and attach them to every possible failure that your program might encounter. For instance, put them into your constraints, in your validations, and whenever a function can return an Error. This way you will not only be able to debug bugs easier when they happen, but it also helps your testing setup. In particular I'd recommend also writing at least one test for each Error case, which should get you pretty good code coverage if you have written many Error cases.
I know, it's a lot of annoying little work, but this will improve your code quality significantly, and you'll catch bugs before they hit production.
Daily Solana Tip 18
Set up multisigs for your programs authorities, such as the upgrade authority, or internal admin authorities. For a deeper framework on structuring protocol authorities, see Designing Better Authority Structures. These multisigs should protect you from multiple scenarios. First of all, loss of keys, such as accidental deletion or a broken or lost device. This can be prevented by slightly reducing the threshold of the multisig (and ideally by having proper safe key backups), so that in the case that a member can't vote, the multisig can still do something.
The next scenario you need to protect against is key compromise. This means that someone malicious gets their hands one or more members keys. To protect against this, you need to set the threshold high enough that the malicious parties can't do anything by themselves, but also not too high to not give them a superminority allowing them to block the multisig.
Lastly you might want to consider a legitimate dispute between members. What kind of majority should be allowed to dictate an action?
All this can be distilled into a few rules:
(n/m Multisig means n out of m Multisig, means m members with a threshold of n)
1/m should not be used for most cases - they just give full access to any member key
m/m Multisigs should also not be used - each member can hold the multisig hostage, or loss of a single key leads to loss of the multisig as a whole
Therefore the smallest multisig that makes sense is a 2/3 multisig. It gives minimal protection against one member losing their key or turning rogue, because the two other members can always pass a proposal. It also establishes a simple majority vote system.
A 2/4 multisig would be vulnerable to two camps of different opinions being able to pass proposals that the other camp doesn't agree with.
That's why I would generally recommend the formula
floor(m/2)+1 / m
for multisig configurations. This translates to
2/3, 3/4, 3/5, 4/6, 4/7, etc. being good configurations.
Also, sometimes it makes sense to give some people more rights within the multisig, which could translate to giving them two membership keys instead of just one. Similar to multiple board seats.
That's it, keep your programs safe, and use a proper multisig. If you wonder which multisig to use, I'd recommend @SquadsProtocol
Daily Solana Tip 19
It's important to be ready for the worst case. If you are running an on-chain program, it is a real possibility that someone finds a bug in your program and exploits it, causing Loss of Funds for you and your users. And the reality is that this can happen even to well-audited projects. Therefore I recommend having a plan for when shit hits the fan. Because when it happens, you'll be in panic mode and won't be able to make the best decisions. Here are some things to prepare now: Make a incident document that outlines the whole process. You should have a section with key contacts, such as a lawyer, law enforcement, auditors, bridge/cex/stablecoin contacts who may be able to freeze tokens, key stakeholders, and ways to contact them securely. Next, you should predefine responsibilities within your team: Who is tasked with fixing the issue, who is tasked with communications, and who is tasked with investigating the hack?
You should have a predefined way to pause the contract, be it through a program upgrade and a pre-written frozen contract fork, or through a admin instruction.
Ideally you have some prewritten and lawyer-approved messages for your community.
Preparing all this and never needing it is so much better than not preparing anything and then needing it. Obviously there is much more you can prepare for such a situation but that's enough for today
Daily Solana Tip 20
When doing financial math, you're typically using uints. Let's consider their basic rounding. Rounding occurs on any operations that would yield a non-integer result, but is rounded to a whole integer. In rust, these are generally rounded down.
For example:
2_u32 / 3_u32 = 0_u32 (0.66)
3_u32 / 2_u32 = 1_u32 (1.50)
5_u32 / 3_u32 = 1_u32 (1.66)
Play around with it here.
What does it mean for us? It depends on what we are calculating. If we are calculating the amount of tokens the protocol should give to a user, rounding down is good. If we are calculating the amount of tokens a user should give to the protocol, rounding down is bad. Generally, we want to err to the protocol's advantage, otherwise we may become vulnerable to salami slicing attacks.
When going through your code, find places where rounding happens and think to whose advantage you are rounding. Make sure no user can gain an exploitable advantage.
Daily Solana Tip 21
Another source of issues in Rust similar to rounding are type casts.
In Rust, we can use the as keyword to cast types between each other. For example, 1000 as u16 , or 1000 as u8. The first one will result in 1000_u8 , while the second conversion will truncate the number to 232_u8 , because u8 only can track numbers up to 255.
Therefore, we need to be careful when casting numbers into a type that may not fit it.
When casting floats to ints, rust will perform a saturating cast. For example, 300.0_f32 as u8 will return 255. If we performed this cast 'raw' using to_int_unchecked:: , it would return 44.
Generally, it's safer to use ::from and ::into methods instead of as to cast your numbers in rust. If you must use the as keyword, make sure that no unexpected truncations can happen.
You can find good learning material here: https://doc.rust-lang.org/rust-by-example/types/cast.html
Daily Solana Tip 22
Once you've deployed a solana program, it's crucial to make sure it's running correctly. So let's talk about program monitoring. There are multiple things we can monitor about a program: - instruction calls and their values - global state accounts - TVL - fees - new account creations - events The easiest one is probably monitoring pre-defined accounts, because you can simply poll them at regular intervals. When you have the program's IDL, creating a monitoring script with anchor is simple. The following script will observe MetaDAO's main DAO account, reading the proposal_count field every 60 seconds and alerting us on a change. This is frankly the simplest form of program monitoring, and not very sophisticated, but it's a good starting point.
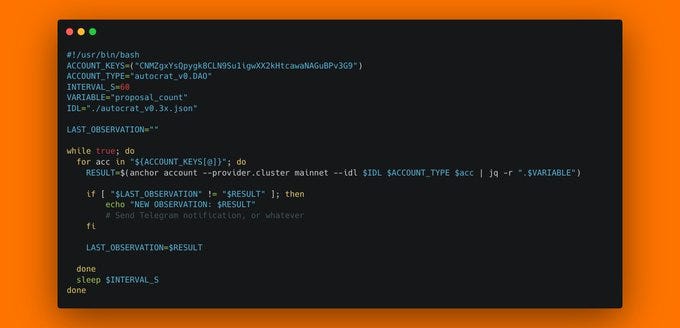
Daily Solana Tip 23
You want to gate access to your app to whitelisted users? There are a few patterns that allow this. The first one would be NFT gated access. In this case, the user provides a signer wallet, and an NFT token account of a predefined collection this signer owns. It's important to check that they actually not just own this token account, but also amount = 1 , otherwise an attacker could bypass the check with an empty token account (seen this before...).
A second popular pattern is gating the sign-up instruction through a whitelist PDA. Such a PDA has the seeds ["whitelist", whitelisted_user.key()] , or something similar. The whitelisted_user has to sign the transaction, and provide the PDA account, which has been previously created by the administrator.
Another possible solution would be a single whitelist account with a Vec containing whitelisted accounts. I'd recommend using the PDA solution over this though.
Lastly, another elegant solution could be a merkle tree. This allows you to define the full whitelist through a single root hash, and users can show an inclusion proof to access the gated instruction. This method has a very low on-chain footprint, but requires more off-chain engineering to provide the full merkle tree to users and you need to implement proof generation.
Daily Solana Tip 24
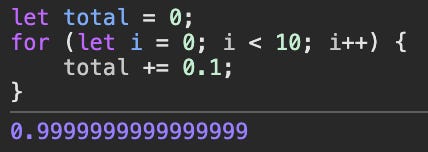
What's the best way to represent $420.69? It's a number with a point, so a floating point might sound like a good candidate. This is a horrible idea. Why? Because the number represents an asset value. It has to be super precise. Would you be happy if your bank balance was $100, and after you deposit $1 , it's $100.99? Something like this can happen with floats, because they inherently approximate numbers due to the way they work. In short, floats use binary fractions, while what we want in finance are exact decimal numbers.
To give you some examples:
0.1 + 0.2 = 0.30000000000000004
0.1 + 0.1 + 0.1 + 0.1 + 0.1 +0.1 + 0.1 + 0.1 + 0.1 + 0.1 = 0.9999999999999999
In addition to that, letting users provide floating point inputs can lead to unexpected bugs, because floats implement special numbers such as +0 and -0 , NaN , +inf and -inf. Instead, you should always use integers, ideally unsigned. For example, you can represent $420.69 as 42069 , and define it as number of cents. You can also scale it up and represent it as 42069000 , or an even larger number to gain more precision in your calculations. Remember: Friends don't let friends use floats on-chain.
Daily Solana Tip 25
When you're building a larger program, there are two design philosophies:
-
Put everything in one big program
-
Split the program into subcomponents creating a multi-program architecture
Putting everything into one program is self-explanatory, and I want to talk about the other option - splitting your program into components.
First of all, an example. Let's consider MetaDAO. It implements a system with multiple DAOs, proposals, splitting tokens into conditional tokens, and trading them. You could stuff all that into one program, but instead, they opted for another architecture. There is the Autocrat program, which handles DAOs and proposals, and acts as an authority. Next, we have a separate conditional vault program, which is responsible for splitting and merging conditional tokens. And lastly we have the AMM, which is the part where the trading happens. This architecture brings some advantages: First of all, it's modular. This means separate components can be used on their own, and also updated or swapped out. But one of the best parts is that it creates privilege separation. On solana, programs are allowed to write to their own accounts. Using a multi program architecture, you can make sure that some accounts can only be written by some parts of the code. In the MetaDAO example, no condition vault code will ever change a proposal account. And because CPIs are cheap, this is a great pattern to use.
However there are also some drawbacks to a Multi Program Architecture. First of all, it can make the program more complex. Second of all, the runtime restricts you to a call depth of 4, and a max number of CPI calls of 63. So, basically don't overdo it with the CPIs. Lastly, you introduce some operational complexity. For instance, when introducing an update in one of your subprograms, you may also need to update the other programs to support the changes. So ideally, you want to update them at the same time, or at least pause operation while one of the programs is updating. This can be tricky. Nonetheless, I recommend a multi program architecture for bigger programs. You can implement a global state variable with an updating state to address this last issue.
Daily Solana Tip 26
One common bug in Solana programs that don't use frameworks like Anchor is in account creation, which programs do all the time. New accounts are created and allocated by the system program, which provides the handy function create_account for this purpose. Instinctively, using the create_account function should be the perfect way to just create a new account and be done with it, right? The problem is that it has a catch: create_account requires that the account to be created has 0 Lamports. If you're familiar with Solana, you may know that anyone can increase any other accounts Lamports, basically by doing a transfer. Ergo, anyone can make your create_account call fail by transferring a single Lamport to that account. All they need is to know the account address ahead of time, which is normally the case with PDA accounts.
So what should you do as a dev instead? Well, you have to do manually what create_account would have done for you. This means, allocate the required space, transfer the remaining rent, and assign the account to your program.
Frameworks like Anchor handle this for you behind the curtain.
Daily Solana Tip 27
One quick way to find a Loss of Funds bug in solana programs is to look for invoke_signed calls that a program does, and check if the called program is verified correctly. In the worst case, an attacker could supply an arbitrary program to be called, receiving a signature from the caller, allowing them to drain all signers. Also, be aware that signers extend to CPIs.
Therefore, whenever your program invokes other programs, really make sure to check the callee address.
Daily Solana Tip 28
Be aware that whenever your Solana programs interact with other programs, you're introducing counterparty risk. If their upgrade authority is compromised, their program is exploited, or even if their program is upgraded and old structures or instructions become obsolete, your program could become simply unusable, or in the worst case exploitable, or directly be losing funds. Therefore, it's good to have some policies in place when integrating outside programs.
First of all, non-upgradeable programs mostly just contain exploitation risk of the existing code. They can be used with the least concern if the code is solid and well audited.
For upgradeable programs, you should make sure that their upgrade authority is well protected, ideally through a multisig. Next, you should make sure that you call their program with the least possible privileges. Try to pass as many accounts as read-only as possible. Only pass writeable accounts or signers if absolutely necessary. Ideally design the calls in such a way that if their program became malicious, they could not fully drain your program, and the damage would be limited.
Daily Solana Tip 29
A quick way to find many potential improvements and to uphold a high coding-standard is linting your program with the most annoying lints possible. For example, running something like
cargo clippy --all -- -W clippy::all -W clippy::pedantic -W clippy::restriction -W clippy::nursery -D warnings
will likely yield hundreds of suggestions. You can go through the output of this, dismissing most suggestions as overly pedantic and looking for the occasional reasonable improvement.
You don't have to do this every time you compile your project, but it's good to check from time to time.
Daily Solana Tip 30
A bug pattern that I see from time to time happens when Vectors are used and their content is verified one by one in a for loop.
The bug here might seem obvious - what happens when the vector is empty? The for loop is entirely skipped and the checks pass, executing the code after the for loop. Sometimes this isn't an issue at all.
But sometimes the code after the for loop should only be executed when valid elements were present.
The solution is simple: Require that the vector isn't empty!
Daily Solana Tip 31
When you have a program's IDL, it because very easy to build a client for that program. If you're building in Rust, Anchor provides the declare_program!() macro, or you can use Sanctum's solores. In TS, you can also use Anchor's typescript library, or Metaplex's solita (seems unmaintained though).
There are also numerous online tools, my favorite being
, which can import an IDL or an on-chain transaction, and allow you to change some parameters and re-send the transaction.
Also, IDLs, don't just allow you to build clients, they enable you to decipher on-chain data. For example, using
anchor account --idl some-idl.json targetprogram.TargetAccount 11111SomePubkey1111111
you can easily read and deserialize the on-chain account 11111SomePubkey1111111. IDLs are your fren
Daily Solana Tip 32
One of the most popular Solana programs by usage is the Associated Token Program. It solves the following problem: You want to send tokens from your wallet to someone else's wallet, but they don't have a token account for that specific mint yet. That's how Solana's account model works - there's no automatically pre-allocated recipient token account for them. It has to be created.
You could solve it simply by creating a random token account and assigning it to them. Send the tokens to that account, and now they are in possession of the tokens. Easy enough, right? Well this just kinda works. The problem is that they will not be able to find these tokens easily. It's like opening a trust for them somewhere across the globe, and not informing them about it. It could also be the case that they already had a token account for that mint, but you just didn't know about it. Or they might have multiple token accounts for a mint already. The associated token program solves this.
It defines a deterministic way to derive an address for their specific wallet, the token mint, and the token program in use. The address is a PDA of the associated token program, commonly called an associated token address, or ATA. The associated token program lets you allocate a token account at that address, and it will assign ownership to the wallet that it is derived from. This derived address is then often used as the main token account for that specific mint, and it will be easier found by indexers, wallets, and senders.
In another daily tip I've mentioned the possible footgun of using "init" with ATAs, because anyone can create an ATA thus blocking the init. Actually, the ATA program provides a practical built-in solution that you might have seen onchain: CreateIdempotent - which will try to initialize a new account, but will return gracefully in case it already exists.
Another fun fact - ATA's don't guarantee that the wallet it is derived for is the token owner, because after being assigned, the token owner could just reassign that token account to another owner. However, this doesn't work with token22 ATAs, because those are initialized with the immutable owner extension.
You can calculate an ATA in your command line using
solana find-program-derived-address ATokenGPvbdGVxr1b2hvZbsiqW5xWH25efTNsLJA8knL pubkey:$WALLET pubkey:$TOKENPROGRAM pubkey:$MINT
Daily Solana Tip 33
If you're a Solana dev or auditor, you're probably familiar with the Token program. The program allows you to do all the expected things: create new token mints, mint, burn, and transfer tokens. But there are a few lesser-known functionalities: First of all, the mint of a token (think of it the configuration of a currency as a whole) can contain a freeze authority. This is a defined pubkey which is allowed to freeze token accounts - meaning they won't be usable. Obviously, such a feature is dangerous and could be used for rugs, so it's common practice that this authority is fully revoked together with the mint authority.
Another feature is delegation - a token account owner may delegate some of their token balance to a different account, which means this different account will be allowed to spend this much of the token account. This delegation can be revoked at any point.
This feature was created so that users can delegate some amount to a program and be sure that the program will not withdraw more tokens than delegated, but in practice it's rarely used (I don't think I've seen any production program actually using this).
The last uncommon feature of the Token program are Multisigs. The token program allows the mint authority, account owners or delegates to be defined as M out of N multisigs, another feature that is practically never used in lieu of more thorough multisig implementations such as squads or realms.
Another thing you should know about the token program is that user token accounts may be closed at any time by the user. This can turn into a bug pattern if you try to build something like an airdrop program that collects token accounts in a list and then in a single instruction tries to send tokens to all defined token accounts in that list. If one of the users closed their token account, the transfer may fail.
Generally it's almost never advisable to hardcode or save user-closeable token accounts anywhere within your programs. Instead, you should just save their authority, and allow for any of their token accounts to be used.
The last little feature I want to mention is that token account ownership is transferable. This means when I have a token account containing 1 USDC, instead of sending that USDC to you using the transfer instruction, I could also reassign ownership of that account to your authority. Sounds like a silly quirk, but in theory this could be used to circumvent transfer fees (which aren't really enforceable anyways with the old token program, except when using a freeze-unfreeze pattern), or keep transfers hidden from prying eyes - more on that another time ;)
Daily Solana Tip 34
The solana cli is super powerful and basically fully replaces the solana explorer.
get info about a solana account:
solana account $PUBKEY
get transaction history for an account:
solana transaction-history $PUBKEY
get full information about a transaction:
solana confirm -v $TRANSACTIONSIGNATURE
get block information:
solana block $BLOCK
stream live transactions logs:
solana logs
It's all right there - what else do you need?
Daily Solana Tip 35
The old solana token program was extended last year by adding a new token program called Token22. Why is it called token22? No one knows. They probably wanted to launch it in 2022, to beat etherims timeline of token2049. Anyways, the updated token program includes many interesting extensions, while also supporting classic token features 1:1. New extensions include features like confidential transfers, transfer fees, closable mints, non-transferable tokens, permanent delegates, transfer hooks, required memos on transfers for your token accounts, immutable ownership for token accounts, default account state (e.g. frozen on creation), cpi guards, and also some non-functional extensions such as interest-bearing tokens, metadata and metadata pointers. That's a lot of features, and especially a lot of things to think about when trying to implement token22 tokens in your protocol. Many of the features are relatively harmless, but some should be considered with great care when implementing token22 support in your programs. For example, transfer fees mean that deposits and withdraws are subject to fees. Closeable mints can be very dangerous, and you probably don't want to support them. Permanent delegates can always take funds out of your protocol treasury.
I want you to think about each of the extensions, how it may affect your protocol, and make a decision if you want to support it, or not. Then whenever someone introduces a new mint to your protocol, disallow it if the mint in question implements one of the extensions you don't like, for example the permanent delegate. In another tip, I will show you how to implement this easily.
Daily Solana Tip 36
Did you know that if you want your protocol to accept both native sol and spl tokens as deposits, you don't have to implement both versions. Instead you can just implement the spl token version, and users will be able to deposit their native sol as wrapped Sol.
Now an interesting fact about wrapped Sol:
wSol isn't some derivative issued by some third party. No, it's actually native to Solana, and has its own little special implementation within the token program.
To create wSol, you create a token account for the native mint, which is **So11111111111111111111111111111111111111112**. Then, you send Sol to that account, and call the token program instruction **SyncNative**, which will update the token account's amount to the Sol that you have deposited minus the rent. Now you can use the token account like any other token account.
To unwrap Sol, you have to close the token account and all the Sol contained in it will be transferred out, back as native Sol.
Daily Solana Tip 37
Let me share a largely undocumented Anchor secret with you: You can define fallback functions in your Anchor program that will be called when none of the defined instructions match a given instruction discriminator. To define a fallback function, you simply add a function with the signature
pub fn fallback(
program_id: &Pubkey,
accounts: &[AccountInfo],
data: &[u8],
) -> ProgramResult {}
into your program module. This function will be called with the original solana entrypoint arguments as shown. Note that you can only define one such function!
Daily Solana Tip 38
How does a program know what instruction is being called? How can a program safely differentiate different account types? The answer is: discriminators. What are they? And no, they won't get you involved in a DEI lawsuit. Discriminators are the first few bytes in an instruction's data or in an account. For example you could simply use a single byte discriminator. Then, if the first byte of the instruction data is 0x01, we call the first instruction in our program. 0x02, call the second one. And so on. In practice, Anchor uses 8 byte discriminators, and they aren't enumerated like 1,2,3. Instead, anchor hashes the instruction name together with the namespace global. e.g. sha256("global:initialize") for the initialize instruction. When your program is then called, Anchor's dispatcher checks the first 8 bytes of the instruction and iterates through a list of these instructions hashes to find the one that matches. When there is no hit, the fallback function from the previous tip is called! Anchor accounts work the same way, and when you write a native Solana program you should also use discriminators for your accounts: Each account type that your program has should have a unique identifier sequence that you put at the beginning of the account to prevent account confusion attacks. Whenever your program loads a given account, it should check the account owner and discriminator first.
You may know that some programs don't have discriminators - for example the token program. The two main account types of the token program are the Mint and TokenAccount , and instead of using a discriminator they are often distinguished through their account size. However, this approach can have its problems when your program also supports a variable length account, like the Token Program's Multisigs. Though, in the case of the Token program, it's not a problem. TokenAccounts are 165 bytes. Mints are 82 bytes, and Multisigs are 3+n*32 bytes, which is never 165 or 82. Therefore, when an account owned by the Token program is 165 bytes long, we can be sure that it is a TokenAccount.
Daily Solana Tip 39
Rust has two important types of comments that you should know: // and ///. The two slashes are just regular good old comments. Use them to add context to your code, comment out stuff during development, or justify your bad coding style. If you're a gigachad developer, you would also add a short comment describing the mathematical function you've implemented whenever you do some calculations in your code. Now the triple slashes are docstrings. You put them in the lines before you define a structure, field, method, function, or whatever. This docstring supports markdown syntax and can be used to generate HTML documentation. Many editors will also support showing docstrings for objects when you click or hover above them, making developing much more comfy. I strongly recommend adding docstrings to all your structs and struct fields (such as in account structs in anchor), and your helper or library functions. Anchor also takes the docstrings you created for your structs and puts them into the generated IDL!
Daily Solana Tip 40
Solana has many unique bug classes and this is one of them: Account Revivals. This happens when programs try to close an account by just setting the accounts lamports to zero. At the end of the transaction, Solana's garbage collector should then delete the account because it has no rent. However, this is vulnerable because the attacker could transfer some sol back into that account after the defunding and before the transaction ends. Now the program "thinks" it has deleted the account, but the account will keep existing.
If the account was for example a single use white list ticket to sign up on a platform, an attacker could reuse this ticket now!
A better way to properly delete accounts is to completely zero them out and assign a special deletion discriminator to it. This way, the account can not as easily be reused after being revived. However, it doesn't fully fix the problem, as the account will still exist, and have data in it, be it all zeros. Therefore the actual best solution, which is implemented in anchor's close constraint, is to defund the account, reassign the account to the system program, and reallocate it to 0 bytes. Basically doing the account creation process, but backwards!
Actually, I believe the original solution with the constraint, which used to be in anchor as well, was used due to the fact that solana didn't support account resizing for a while. So the only way was to change the data in the account and get it fully deallocated by the garbage collector.
Daily Solana Tip 41
Reading solana onchain data can be tricky and thats why some devs resort to a simple but dangerous trick: at the end of their instruction, they log some data, like " pubkey 11112222233334444 (username r0bre) deposited 63728918 lamports ". In their offchain code, they then monitor their program logs and parse the required data from the logs, instead of the instruction data. Well, don't do this. Logs are easily manipulated: first of all, in the above example the username is part of the log. What if we change our username from " r0bre " to " r0bre) deposited 777777777777 lamports\n "? This may throw off the parsing and might get us a large deposit coupon! This attack is called Log Injection.
Another way to confuse the offchain log parser would be to make the transaction fail. The logs will still be produced, but the deposit won't go through. Yet another way to confuse the logs is to call the program in question as a cpi and create similar looking logs from the caller before or after the call. Bad parsing implementations may pick up the caller logs and interpret them as callee logs if they look similar enough. The last thing to know about logs is truncation. When logs grow over 10kb, they get cut off. Overall I recommend not parsing logs at all. Use events as I described in another daily tip about solana logs!
Daily Solana Tip 42
To understand Solana, you need to understand the Solana account model. Unlike on some other blockchains, Solana programs don't automatically have their own storage. The only way programs can persist data on the blockchain is by writing it to accounts. Think of accounts as files that are all stored together in one big directory called the ledger. Each account has a filename - its Pubkey. In addition to that, each account has some metadata: Its owner, which is a reference to another account, its Sol balance, and its executable flag, which marks accounts containing program code.
Solana enforces one important property: Only the owner of an account may write to it, except for increasing its Sol balance, which everyone is allowed to do. Every account is owned by the System program by default, until the System program changes the owner to another program. And only the system program can allocate space for data for accounts.
To do anything to a new account, the system program requires a Signature for that account. Note that it's not the runtime or SVM, it's the System program asking for the signature here. The runtime will just validate the correctness of signatures.
Once an account is reassigned to your program, it is now your program's job to manage access to this account. Your program can fully ignore Signatures for this account's Pubkey and the owner of the Private key will not be able to do any writing to the account anymore. Now that your program owns this account, it can write data to it and reduce its lamports. As the owner of the account, your program however can't sign for the account, except if it was a PDA.
When taking accounts as inputs it's always important to check the owner of the account before reading its data. Because that's the program you trust to have put data into the account.
Daily Solana Tip 43
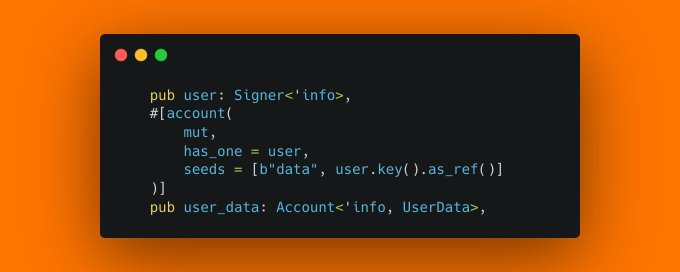
I sometimes see this pattern where a constraint checks a relationship to another account by seed and by has_one at the same time. Oftentimes, this double check is redundant and just wastes CU. This is the case when the field checked by has_one is practically immutable. So in the given example, there is no code that will ever change the user field in the UserData struct after initialization. Instead of this double check, it's ok to only check the has_one relationship! But don't be too pressed about it, redundant checks can be good as well, especially when maintaining a codebase that's updated occasionally - redundancies can help to reduce the risk of a future update accidentally bypassing a single check.
Daily Solana Tip 44
Are you annoyed with the bloat when writing a small simple Solana program? Like why is the binary so big? Why does compilation take so much time and why does it use so much CU? Where do all these dependencies come from? Well I have a solution for you! You can use anza's pinocchio instead of solana-program and it provides all the important basic solana features for your program with much less bloat. No dependencies! But be careful: when using minimal frameworks like this you take on the responsibility to implement security features yourself.
https://github.com/anza-xyz/pinocchio
Daily Solana Tip 45
Who pays transaction fees? In Solana, the first signer of a transaction is the designated fee payer. This signer is verified as the fee payer before the runtime starts executing instructions, and will also be charged when the transaction throws an error and is reverted. This means multiple things: The fee payer must be a System account. If it was a program account and the transaction reverted, we couldn't charge it, because we don't have the program's approval. Also, this means that the fee payer is not only writeable, but is also written in case of transaction failure, which is an interesting side effect. It means that a personal multisig like fusewallet has to always keep some funds in a non-multisig account to pay fees. But it also means that we can have a different fee payer and signing authority.
Note that the transaction fee payer is not automatically the account that pays for rent allocations, even though this is often marked as "payer". Programs can define any signer to be the dedicated payer for those!
Daily Solana Tip 46
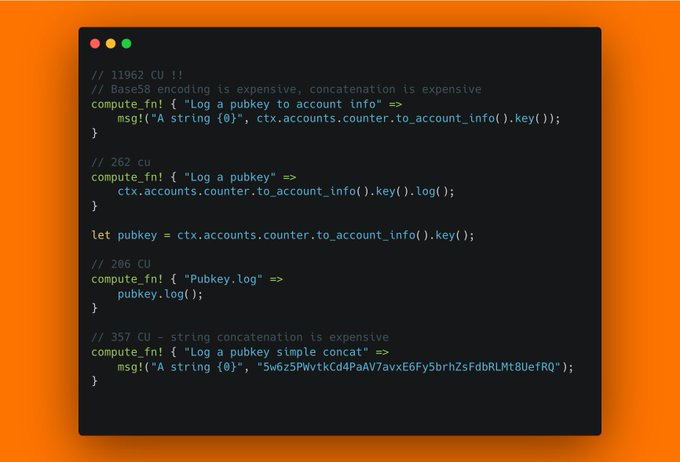
Want to benchmark your program's CU usage? Actually, that's quite easy! You can simply use the solana_program::log::sol_log_compute_units() function to print the current CU usage. And if you want to make it a bit nicer, you can define a macro to create a nice CU usage printout for your measurements. For example, you can use the compute_fn! macro defined here:
https://github.com/solana-developers/cu_optimizations?tab=readme-ov-file#how-to-measure-cu
Using this, we can figure out that logging a pubkey using its string conversion after doing to_account_info is quite expensive! Using the built in Pubkey.log() is much cheaper
Daily Solana Tip 47
Need help landing transactions? Let me introduce you to two variables: Compute units and priority fees. When your program does computations, it uses compute units: More work means more CUs, and when it does less, it uses less CUs. Now, by default, the scheduler doesn't know how many CUs your program is going to use. That's why it can be useful to add the setComputeUnitLimit instruction to your transaction, which will tell the validator that you will only use up to X CUs! This way, the validator can more easily schedule your transaction efficiently. To know how much to request, you want to simulate your transaction and request about the simulated amount with some buffer. Note that CU's may fluctuate for different Signers, Pubkeys, or on-chain state, so you should simulate a couple of different scenarios and make sure to provide bumps! Now, in addition to that, you may want to add a priority fee. You can define how many micro-lamports you want to spend per CU using the setComputeUnitPrice instruction, which will add an additional fee paid to the validator, incentivizing them to include your transaction. Now you'd think that using a high fee you can make sure your transaction will be included instantly and always, but unfortunately that's not true at the moment. Someone paying a lower fee might still be included before you due to scheduler internals. But you stand better chances with a fee than without. These days it's almost best practice to always include a small priority fee.
Daily Solana Tip 48
Always be careful using slots boundaries or epoch boundaries as a change of program state. Using jito bundles or as a validator, someone can be the last to interact with your program before the state change, and the first to do so after. Sometimes this opens up vulnerabilities or other opportunities for attackers. Be sure to design your program in a way that they shouldn't gain an unfair advantage through bundles crossing these state transitions!
Daily Solana Tip 49
You might have heard this term floating around: Zero Copy. Let me help you understand it. When your program handles large accounts, you want to avoid any unnecessary copies that typically happen during deserialization - they just are too costly. When deserializing your account data, normally anchor will copy all the given data and put them into a new deserialized structure.
Zero copy is a programming pattern where instead of copying data, the program operates on the same set of data without copying, only passing around references and working on the same set of data. During Deserialization this means that we don't create copies, instead we overlay the deserialized structure exactly on top of the existing byte array.
To use zero copy with anchor, you need to annotate your accounts with the
#[account(zero_copy)] attribute which will implement necessary traits, and in your constraints you can then use AccountLoader <> instead of Account <>. When you then use the account in your instruction, you will need to load it using the load_init() function on initialization, and using load() or load_mut( ) when you want to read or write a zero copy account.
Use the zero copy pattern to work with very large on-chain accounts, or when you want to reduce CU usage. Note that with zero copy discriminators aren't checked until the account is loaded. So if you never load an account, your instruction could be vulnerable to account confusion attacks.
Daily Solana Tip 50
Solana's System program enforces a maximum account size of 10MB. To store this amount of data, you need to pay 73 Sol for rent exemption! Now that could be just a simple fact, but in practice there's more to consider. Because accounts that store data are going to be program-owned accounts, we probably would prefer using PDAs. Now however, with PDAs we run into the following issue: PDAs have to be created through a CPI and can not be created through a top level instruction. And CPIs have a fun restriction: Accounts can not grow by more than 10240 bytes during a CPI. I suppose that's because when you call some other program, and the program returns an account that is over 10240 larger than before, your memory management can become tricky.
This means that when your program needs to use accounts larger than 10240 bytes, you have two options. The easy option is to use a Keypair-account, allocate it outside of the program and assign it to your program, getting you up to 10MB quite easily, but you won't have a PDA. The other option, if you want to use PDAs, is that you reallocate step by step, in 10240 byte increments, until you reach your desired account size. To do the first of the two versions, you can use anchor's zero copy and the #[account(zero)] constraint when initializing the account, indicating that it's an allocated account full of zeroes.
Note, when you look up this information, you'll get a lot of confusing statements. Let's clean this up: Solana accounts can be 10MB large. Your anchor program can't easily allocate such a large account as a PDA, because it would have to use a CPI, and CPIs restrict accounts from growing by more than 10240 bytes at once. PDAs can be larger than that though, you just need to reallocate them in multiple CPIs.
Hope that clears things up!
Daily Solana Tip 51
Ever run into stack frame errors when adding lots of accounts to your instructions? Or when using big accounts? Or when your functions get long? You should know that Solana gives you just 4KB of stack space, and 32KB of heap space to work with. Also, you should know that anchor will put your deserialized accounts onto the stack by default. So what can you do? First of all, you can make Anchor allocate accounts on the Heap by wrapping them in _Box <> _in the Accounts struct, but know this requires the accounts to be deserialized into a defined struct. Another way to prevent stack errors is to make your functions shorter by splitting them into non-inlined sub-functions. That's because new fresh stack frames when functions are called! You can also put unused accounts into the remaining_accounts by not defining them in the Accounts struct, but be aware that you have to be really careful if you end up manually validating them. Another way to save stack space is to use zero copy as I've described in a previous tip. This does not allocate new space for your accounts, but re-interpretes the given accounts byte blobs as a given structure, saving you stack space.
Daily Solana Tip 52
Solana is ever changing - whatever you have learned about it a year ago might not even be true anymore. That's because there's active development going on, constantly improving the chain and adding new features. New ideas are proposed through Solana Improvement Documents (SIMD). You can find them on github. Currently there are many discussions about SIMD 228 to change Solana's staking rewards. SIMDs give you an early look on upcoming Solana features.
New features are typically activated through feature gates. They represent ready to go implemented features waiting for activation. Those you can find by running solana feature status in your terminal. Each feature has a pubkey, and can be activated by a core dev at a certain slot for all validators at the same time.
Normally, features are first tested on testnet, so you can check out there what features are being tested right now!
It's always a good idea as an auditor or dev to keep an eye on new SIMDs and features to know what's changing in blockchain internals. Sometimes old restrictions are lifted, or new restrictions could be added directly impacting your work.
Daily Solana Tip 53
Solana uses a pretty simple heap implementation that limits you to 32KB of heap space and doesn't even let you free up memory: A bump allocator. This is the most simple heap implementation imaginable. For example: The first 8 byte allocation gets you some memory at 0x0, the next 16 byte allocation gives you some memory at 0x08, and the next one at 0x18. You just keep bumping up the allocated memory, which works until you run out of it. All this allocator keeps track of is where it starts and how much it has allocated so far. Now, this is fine for smaller simple programs. But if your program needs more than 32KB of heap space, or wants to free memory you're out of luck. See our cost of security article for the exact compute unit limits and heap constraints.
Except that rust lets you use your own custom heap implementation! Using the
#[global_allocator] decorator, we can define a heap implementation to use instead of the standard bump allocator. You can use a library like smalloc , or write your own simple heap implementation, or maybe just improve the existing bump allocator, for example by allowing freeing of the last allocated object.
Now there is another trick you can do in theory - Use the ComputeBudget program's RequestHeapFrame instruction to request additional heap space. It works similar to increasing the CU limit or fee, but it has its own problems laid out in the following blogpost I highly recommend reading: https://research.composable.finance/t/creating-the-solana-ibc-bridge-part-1/320
Daily Solana Tip 54
Here's a fun Idea I've picked up from auditing @MetaDAOProject's new Launchpad: creating a sequence number for your events. Every time your program emits an event, it internally increments a number on an account. This allows an external indexer to easily create a sequence of events as they occurred onchain. The drawback is that your program will write to an account more often, sometimes adding a write when there wouldn't have been one before. One way to do something similar without account writes is to just log a timestamp when you emit events, allowing your indexer to sort events by time. However a discrete counter will allow an indexer to not just sort events, but also to make sure it has not skipped any.
Daily Solana Tip 55
Solana programs sometimes depend on external state, time, or other ever changing conditions, and their state or actions should reflect that. For example, a program may want to emit rewards once a day depending on external prices. Or an LST may update its price every epoch. Now the problem is that a program can't just call itself when some time passes, or on other such conditions. On solana, there always has to be some caller who actively calls the program. That's why many programs build so-called crank instructions - those are often permissionless instructions that will advance the state of the program. For example, such an instruction may check the epoch and update price information. Some programs use permissioned cranks, which means only certain users can call them, but the permissionless crank has become a common and widely accepted standard. Now who calls the crank? Oftentimes the program itself is just going to run a cranking script calling the crank in regular intervals. Other times, cranking is incentivized, which means the cranker may receive some funds for cranking, be it in rent returns, actual funds, or receiving an indirect edge by being able to control the first and last instructions before/after the crank. As an auditor there are multiple things to consider about cranks: First of all, permissionless cranks are always an important attack surface within the program. What could a malicious cranker do? Do they have any influence on the state? Could cranker A and cranker B crank in different ways so that the same program in the same starting state will end up in different states? Another thing to consider is the edge that a cranker gains. Can they do some kind of sandwich attack or arbitrage, exploiting prices before and after the crank? If that's possible, is it ok? How bad is the impact when no one cranks vs. the incentive for someone to crank? If there are multiple cranks in your program, what if they get out of sync (one is cranked, and the other is not)?
One way to force your users to crank is to add a cpi or function call to the cranking function to other, frequently called instructions. This way you can have the program be cranked by regular, not crank-explicit, usage. This is often an elegant solution, but requires that you pass the cranked accounts to those other instructions.
Daily Solana Tip 56
Solana transactions are naturally limited by how long the total transaction can be - 1232 bytes, which is derived from the maximum ipv6 transmission unit of 1280 minus network headers. Because transactions have to include addresses of accounts they use, and addresses are 32 bytes long, there is a theoretical limit of 38 accounts that you can pass to an instruction. But in practice the limit is closer to 30 due to additional headers, instruction data, and other passed fields. Now what if you want to pass more than 30 addresses? There is a way: Address Look up Tables (often called ALTs or LUTs). A lookup table allows to prepare a list of addresses on-chain, which then can be referenced from in an instruction as if those accounts were passed directly. To do this, you have to use the new v0 versioned transaction instead of the traditional transaction format, allowing you to specify lookup tables in a separate field. Currently this limits you to use 64 addresses per transaction, though lookup tables can store up to 256 addresses.
To create a lookup table, you need to call the Lookup table program with the createLookupTable instruction, and then add new addresses in batches by using the extendLookupTable instruction, extending the table by 30 addresses at a time.
They work by creating transactions that mention a lookup table, and say "I'm referencing account number 46 of this lookup table". This means that we need to avoid any situation where the address when doing a lookup by reference may change. That's why lookup tables are append only, and can only be created at an address seeded from a recent slot (last 256 blocks) and then can only be closed after 256 slots have passed from creation, so that there is no chance of opening a new Lookup table at the same address and changing what account could be at some index by this method.
Daily Solana Tip 57
Anchor v0.31 is out! And it introduces a new Account type for your constraints: LazyAccount. To use it, you first need to enable the lazy-account feature of anchor-lang. Then, you can use it by replacing Account<> with LazyAccount <> wherever you want. Now what does it do? It's a nice new type primarily for reading singular fields from large accounts. For example, you may have a big account saving a lot of state, but you only need to read a single u64 from it. Now you can use LazyAccount to not fully deserialize the big account, and only load the fields you need. For this, anchor creates helper functions for each field defined in your account struct. For example, if the struct has a authority field, there will now be a function called
ctx.accounts.my
_account.load_authority()? , to read that field only. Now you might wonder, what about security? Well, anchor will in any case also check the account discriminator and program ownership to be on the safe side. You can still deserialize the full account using load() or load_mut() , just like for zero copy accounts. At the moment you only really save CU with this when you load without mut, because mutating will result in the full account being deserialized, though this might change in future versions. So you should know that you'll get the best use out of this type by using it just for reading individual fields from larger accounts.
Daily Solana Tip 58
When you need to measure the passage of time in a program, you can use the clock sysvar using Clock::get()?. (You don't have to pass the sysvar account). This sysvar provides you with the current slot, epoch, a timestamp for the epoch start, the future epoch for which we know the leader schedule, and a current unix timestamp.
The current unix timestamp has a seconds-resolution. It is the timestamp for the current slot, so all transactions within this slot will have the same timestamp. Because slots are just 400ms, this means that consecutive slots may have the same unix timestamp. The validators enforce that this timestamp can only increase and not decrease between blocks.
So, whenever you use timestamps for state changes you should know that, even if you set some expiry value to the current time, the following slot may still have the same timestamp and be within the expiry window.
Daily Solana Tip 59
Whenever your program has some kind of order, offer, proposal, or other account which represents something created by one party, and can be executed or accepted by a second party, you need to consider this. Can the account for this offer be updated, or closed and reopened at the same address? In such a case it might be vulnerable to a TOCTOU attack (time of check, time of use). You might know it from the real world as 'bait and switch'.
Example: Account 420 represents a standing offer created by Bob to buy your rare NFT for 100 sol. It's a good offer, so you send a transaction "accept offer at Account 420". As you're sending the transaction, Bob updates the same offer to buy your NFT for 0.01 sol. He does it either by using an existing 'UpdateOffer' instruction, or by canceling the offer and reopening a new offer at the same Address.
Your transaction lands right after his, and you just sold your valuable NFT for 0.01 sol. Scary scenario right?
Now you might wonder - how did Bob do this? How was he able to get his transaction in just before mine? There are multiple ways to achieve this. For example, you might be using a malicious RPC or Frontend who bundles your transaction. Or, the current leader-validator is the one performing the attack. Or they are running a private mempool and someone else pays them to include their attack transaction before yours. Or, Bob just keeps creating offers like this and then randomly changes them without having seen your transaction, hoping that someone sees the offer and takes it and then gets filled at the cheaper offer. As you can see there are multiple ways someone could try to exploit this. So how can it be fixed? The best solution is to have parameters in your taking instruction that precisely define what offer it's taking. So not just "accept offer at Account 420", but instead "accept offer at Account 420, selling 1 NFT for at least 100 sol"
Daily Solana Tip 60
A common attack pattern for Launchpad type programs where a token is incubated and then released upon a different protocol such as Raydium, Meteora, etc. is pool squatting, or graduation frontrunning. The idea is that the attacker buys the token from the launchpad before graduation and then creates a pool with the same platform that the launchpad would have used. Now sometimes the attacker can create this pool exactly at the address/PDA where the launchpad wanted to launch at. For example when the pool seeds would be "pool" + mint1.key() + mint2.key() , or something similar that's predetermined. If such seeds are used and the launchpad wanted to use a CPI instruction like initializePool , the launchpad graduation will fail. This means funds will become stuck within the launchpad, because the graduation CPI can't create a new pool when one exists already!
To properly graduate to such a pool, the launchpad would need to add liquidity instead of creating a new pool. With a traditional cp-amm that's not so easy. The launchpad would need to first buy or sell into the existing pool until the price matches that of the launchpad, and then it can add liquidity.
Due to problems like this, new pools like raydiums latest amm allow pools to be initialized at non-deterministic addresses. This means that a launchpad doesn't need to worry about being frontran or pool squatted - it can just launch the pool at a different address, and then let arbers take care of price differences.
Daily Solana Tip 61
Solana uses accounts for everything. To store data for your programs. To implement feature gates. To store programs themselves. And also to provide environment information about the cluster to your programs! This is done through special accounts, so called sysvars. These accounts have special addresses starting with Sysvar, such as SysvarC1ock11111111111111111111111111111111. Loading them into your instruction allows your program to access their information, such as the current slot or timestamp from the clock sysvar. Other sysvars include the EpochSchedule, Fees, Instructions, RecentBlockhashes, Rent, Slothashes, SlotHistory, StakeHistory, EpochRewards and LastRestartSlot. All of those sysvars are useful for different things, ranging from calculating rent costs and timestamps to getting information about validator emissions, and transaction introspection. The most used ones are probably the Rent, Clock, and Instructions sysvars, and every dev should know how to use them. Since simd 0127, which was activated just a few weeks ago, sysvars don't have to be included as accounts in the instruction as they can be accessed through syscalls directly. Though programs can still access them through accounts if they want to. In practice, you can simply access your sysvars by using their get method like let clock = Clock::get()?; In the past, we've seen multiple hacks where sysvar account addresses weren't checked by a program and a hacker was able to provide a fake sysvar account. So make sure to check the sysvar address you're using - or even better to use the syscall interface instead of accounts these days!
Daily Solana Tip 62
Every solana account has an owner, which is a program that's allowed to write to this solana account and reduce its lamports. But what about the programs, who owns them?
Well, there are special programs that own programs and are responsible for managing their updates and executing them: Program Loaders. The current loader used by most programs is the Upgradeable BPF Loader. Before that, there existed the now deprecated BPF Loader, which can't be used anymore, and a second version of the BPF loader, which only supports immutable programs. The upgradeable loader supports, as the name betrays, upgrading the program code. This upgrade can only be performed by an upgrade authority. The loader is responsible for creating new programs, upgrading programs, changing program upgrade authorities, and closing programs and their buffers. It also is responsible for executing your program correctly, such as loading its parameters and launching its entrypoint. Currently, the upgradeable loader uses an architecture where your program's code is saved in a separate executable program data account, while the main program account only contains information about where this data account is. (If you've ever wondered why there's almost no data at your program's official address). There is however a new loader on the horizon, which might change how that works. As a dev or auditor you should just know that different loaders exist, but you'll want to use the upgradeable loader with an upgrade authority which can also be revoked.
Daily Solana Tip 63
Normal Solana programs live in accounts - their bytecode is saved on chain, loaded by a loader program (like BPF Loader), and executed within Solana's runtime. They're typically written in Rust, compiled to BPF bytecode, and deployed by developers.
But not all programs work like this. In particular, Solana has so-called precompiles. Those are programs that are built directly into the validator software itself. They have program addresses like normal programs but their implementation is hardcoded into Solana's core codebase rather than stored on-chain.
Why? Performance. Precompiles run directly in native code, bypassing all the VM bloat of regular programs. This makes them significantly faster for common computation-heavy tasks.
Some examples of Solana precompiles include ed25519 signature verification and secp256k1 verification. Those would take a lot of CU in the SVM.. How to use precompiles? You invoke them just like any other Solana program through CPI. For example, to verify an ed25519 signature, you'd call the ed25519_program (address: Ed25519SigVerify111111111111111111111111111) just like any other CPI
Daily Solana Tip 64
Solana tokens historically didn't have a canonical way to store metadata onchain until Metaplex stepped in and implemented their mpl metadata standard. Since then, token metadata, which includes regular tokens and NFTs, are stored in PDAs that belong to the Metaplex program, and are derived from your tokens mint address. (See how compressed NFTs handle metadata differently to reduce costs.)
Now the format of metadata is a bit odd in my opinion. It saves name and symbol onchain, but also a URI that links to a json file stored off-chain on any webserver. This json file contains - again name, symbol, description and a link to an image for the token. Now this design makes it easier to retrieve the information about a token because you can just get it from the webserver json and don't have to get it from the chain. But that brings its own risks.
Metadata can be changed, also onchain, through the metadata update authority. This means someone can deploy a token, and change the name of it at any point! Obviously that brings some rug-potential and most rug-checking tools will flag tokens that have a metadata upgrade authority enabled. What they don't flag however, is a metadata json URI that's serving malleable content. What do I mean? I can use my own webserver to host the metadata json file. And I can instruct my own webserver to change the content of this json file at any point, while the URI stays the same. This way I effectively still have malleable metadata, even though there is no metadata upgrade authority. I can change the name, symbol, description and image of a token at any time, but only the version saved in the off chain json, while the onchain data may stay unchanged. It depends on your wallet, explorer or frontend which metadata will be shown - from the json, or from the chain.
All this can be prevented by enforcing usage of non-malleable data URIs, such as ipfs which acts as a webserver storing its data at a URI that includes a hash of the data in its path. This prevents changing data without changing the URI, and protects your tokens from changed json metadata.
Daily Solana Tip 65
One pattern I've seen a couple times now and I believe can improve your code quality is to define and implement your own traits for Anchor's structures.
For example, you may have a dozen different instructions each with their own accounts, but sharing higher level patterns. For example, each instruction may have an authority, a PDA and a complex way to check authorization to it. This authorization check can be the same across instructions, but the accounts may be different sometimes. You could define a trait for a subset of your instructions to get the correct involved accounts per instruction, and then define the authorization function once on the generic trait. For example, Light protocol does exactly this, and GMX implements their authorization system with the same pattern.
You can also define traits on account types, for example to define common functions you want to have for your accounts such as getting the account size or an invariant check. Using these abstractions you can harness and wield the true might of Rust. Stop being a subject to the language and start making the language your tool
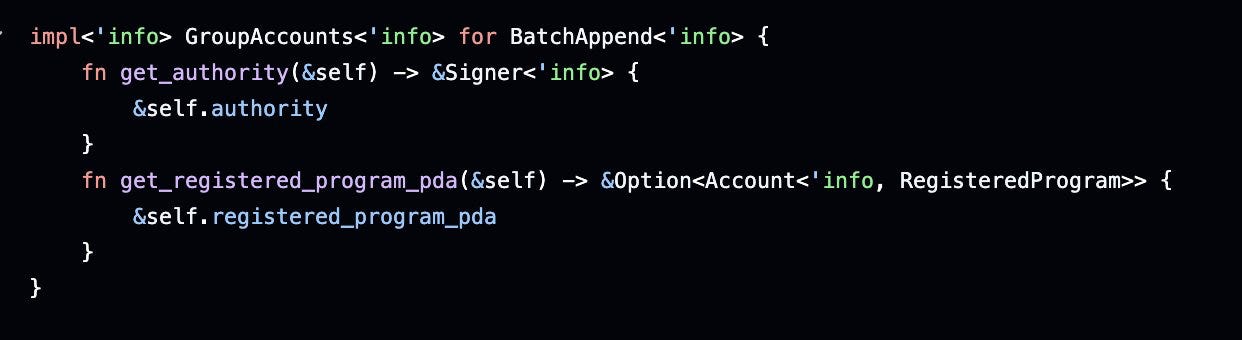
Daily Solana Tip 66
Did you know you can define sub-structures within your Anchor Accounts structs?
Using this pattern, you can define common combinations of accounts as their own Accounts struct, and implement common functions on the nested struct.
For example, your admin instructions may always require a global account and an admin signer. Using this pattern, you can put these accounts (global and admin) into their own structure, define their relationship once, and then just use this structure whenever you want to implement another admin function, without having to reimplement the constraints or validation.
I see this pattern only very rarely, even though I think it should be used more often! Many bugs come from copy-paste errors, or supposedly duplicate code that actually is different.
Using patterns like this you can reduce code duplication and the possibility for errors.
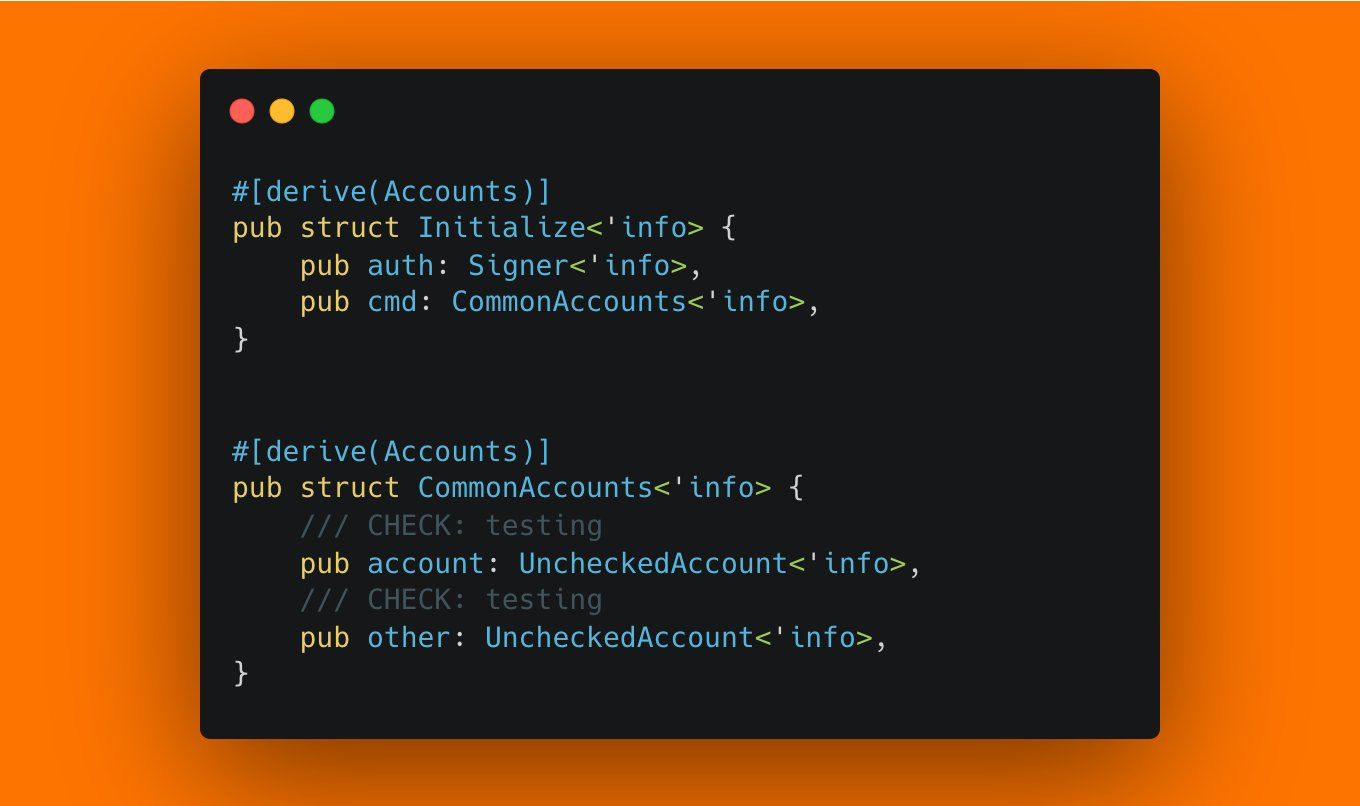
Daily Solana Tip 67
Have you ever seen an Anchor Accounts struct where an account was marked as _Option <> _?
Which means that an account can be passed or None , which is a feature that the runtime doesn't provide natively. So how does your program know when an account is None or Some using Option?
When an instruction is called, Solana passes a list of account indexes to the instruction, each index referencing one of the accounts present in the transaction. There is no official way to supply an index for a missing account. So what does anchor do?
The answer: It's a ruse! Anchor uses a trick to create the None option. When an account has an Option type, it simply defines the program_id itself as the None option, and any other value will be Some! In practice this looks like in the provided screenshots. In the first case, Account #4 is the same as Program , which means that Anchor will parse it as None. In the second case, some other Pubkey is given for Account #4 , so Anchor will parse it as Some.
So, does this mean that None types will not save any transaction space? Because in the None case, we'll have to provide the program id? No! Because providing the program_id just a single additional byte for the id referencing the already-present account.
Now, there are consequences to this somewhat hacky implementation. Imagine we have an instruction that does something like
RegisterProgram { program_to_register: Option <Account>}
We will never be able to call this instruction and register the currently executing program, because this will always be interpreted as None!
Not sure if there is any legitimate scenario where this breaks things, but good to know!
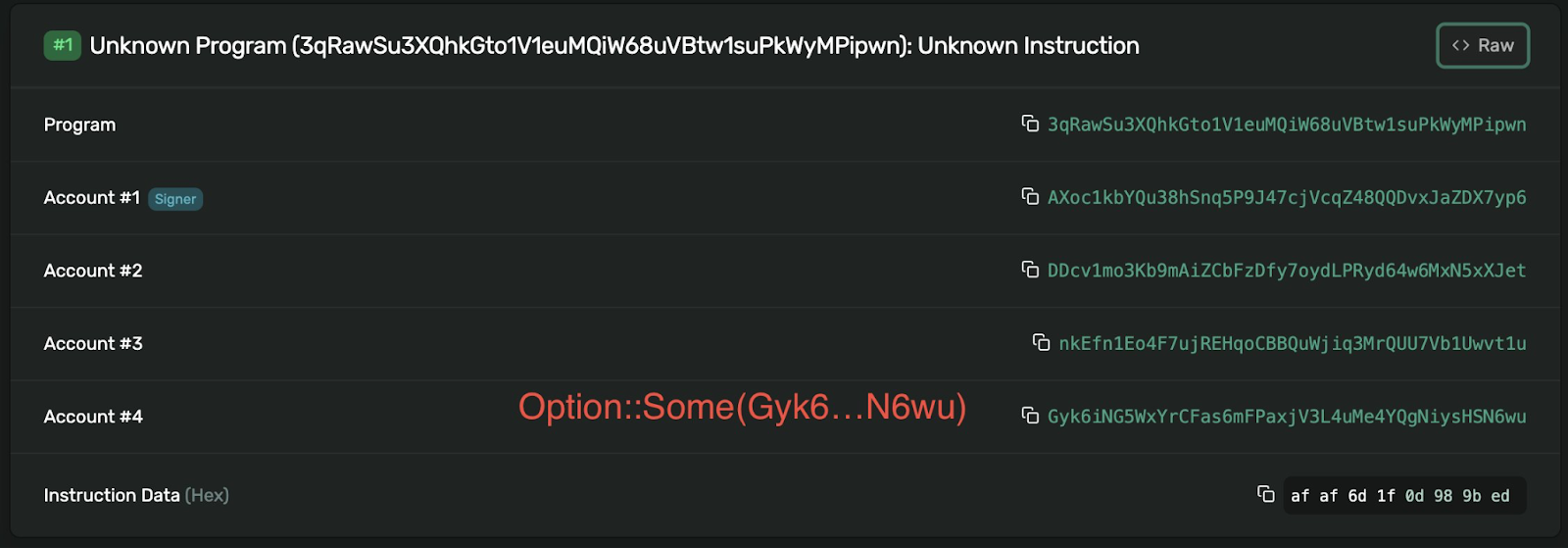
Daily Solana Tip 68
There is a very sneaky bug hiding in Solana programs that try to change lamports "manually" by adding/subtracting lamports of an account directly. In particular there exists an obscure constraint: You can't perform a normal CPI after directly modifying account lamports. The CPI will fail with the error message: sum of account balances before and after instruction do not match.
This is an extremely sneaky bug because all that you're doing is modifying lamports directly (e.g. **info.lamports.borrow_mut() += 1000; ) and then performing some CPI. You're not doing anything wrong per se!
So why does this happen?
Because of the runtime.
Whenever an instruction is entered, the runtime takes note of all account balances of accounts involved in that instruction. Then, when another instruction is entered through CPI, the runtime will update the balances of all accounts in the CPI, and use the last known balance of all accounts not included in the CPI for the balance check.
Here's an example:
Instruction with 2 Accounts: A has 100, and B has 100.
Runtime records this and the total of 200.
This ix then modifies A = 110 and B = 90, and then does a CPI with only account A.
The runtime will then update A = 110, and use the last known value of B as 100, because its not included in the CPI.
So now the runtime thinks the total is 210, which is more than the original 200! It throws an error.
There are multiple ways to fix this: First of all, we can just move all direct account lamport modification after all CPIs, avoiding this problem. Another way to fix this is to include all accounts that have changed their lamport amounts in all CPIs, simply adding them as remaining accounts. This will let the runtime fetch the updated amounts for these accounts, correcting the calculations.
Daily Solana Tip 69
When developing Solana programs, you'll often run into borrow checker issues as you manipulate account data. One elegant solution is using block scopes to limit variable lifetimes.
This pattern helps you:
- Control when borrows are released
- Prevent "cannot borrow as mutable because it is also borrowed as immutable" errors
- Keep your code cleaner by limiting variable scope to where it's needed
- Avoid unnecessary cloning of data
Block scopes are a lightweight way to tell the borrow checker exactly what you intend, without complex lifetime annotations or unsafe code.
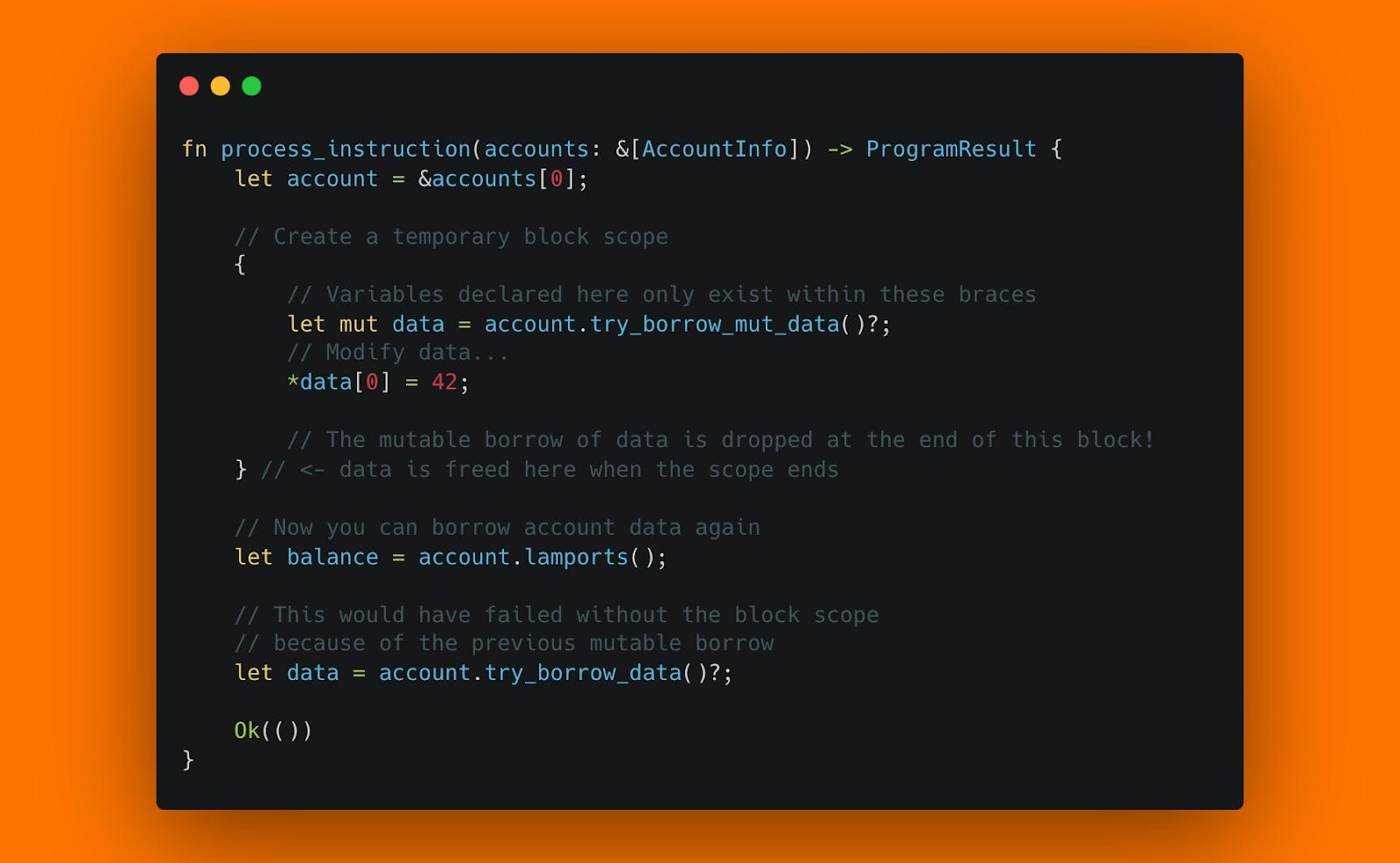
Daily Solana Tip 70
Your program probably keeps some funds for users and for the protocol, be it in Token accounts, or as Sol. Normally, you'd have specific instructions for users to add funds to the protocol - either by depositing, LPing, buying, selling, swapping, locking, staking, or whatever else you can come up with. But you should never rely on your own instructions to be the only way that users can deposit funds. In fact, there is a whole bug category across chains that comes just from this wrong assumptions. Donation attacks. This means that an attacker can hack your protocol by sending funds to your protocols token accounts, or its normal accounts for sol. Remember - anyone can just send you tokens. And anyone can increase the lamports of any solana account without its permission. Thus, if you then use these amounts for calculations within your program, you may get unexpected results. Typically, this is exploited in combination with rounding or other calculation errors that will inflate the attackers claim to deposits in some way. Overall, you should always do defensive calculations where you either account for potential sudden increases in funds, or you keep your internal count of deposits, ignoring the actual funds within an account. If you do this, you should make sure to introduce a special case for when your internal count reaches 0 through a withdrawal - in that case fully withdraw all funds from an account instead of just your last internal count, otherwise you won't be able to close the token account.
Daily Solana Tip 71
When building blockchain applications on Solana, developers often want to incorporate randomness for games, NFT distributions, or fair selection processes. However, implementing true randomness on-chain is nearly impossible and often leads to vulnerable systems.
First of all, blockchains are deterministic by design. Every validator must reach the same conclusion when executing your program. This fundamental property conflicts with true randomness.
Second of all, validators can choose when to include your transaction in a block, influence account values before executing your transaction, and generally front-run transactions.
Third of all, we can build transactions that revert on certain outcomes - for example after calling a random coinflip program, I could call my own program to check if I won the coinflip, and revert the whole transaction if I didn't.
Devs often try the following approaches:
- Using block hashes, slots, or timestamps as seeds (predictable)
- On-chain PRNGs with seed values from accounts (manipulable)
- User-provided entropy (gameable)
If you need randomness in your program, you should rely on an external verifiable random oracle. Another workable approach can be a commit reveal scheme but any such approach should be carefully reviewed by experienced cryptographers.
Generally, it's a good idea to avoid any randomness in your onchain programs.
Daily Solana Tip 72
When managing user deposits with Solana accounts, there's two main approaches: A unified program vault, or multiple vaults ( per user, per pool, etc. )
A unified program pool works like this: You have a global PDA such as "vault" and all deposits to different pools and from different users are all sent to this vault. (or the vault's ATAs). This means that when two users deposit funds into two different pools, the program will update the pool's balances in each Pool account, but the deposited tokens will end up in the same token account, which acts as the main protocol-wide vault.
To withdraw, the same "vault" PDA is passed and signs as the vault authority, no matter which pool we are withdrawing from.
This setup makes it easy to track the protocols TVL, but is potentially more vulnerable to exploits. An attacker who finds a way to steal funds from the main vault could potentially drain all funds at once, becasue it's all in one account.
Now, a different approach can fix this: Using multiple vaults on a per user, or per pool basis. In our example, this means that the protocol creates new ATAs for each pool.
The funds deposited by user 1 into pool 1 will be in the ATA for pool 1. The funds deposited by user 2 into pool 2 will be in the ATA for pool 2.
And because the pool itself is a PDA, we can just use the pool as the signer for withdrawals, instead of using a global authority PDA.
This approach protects funds in one pool from attacks targeting another pool. However, this approach makes getting a protocols TVL much harder, and is one of the main reasons that getting a Solana protocol's TVL is difficult. You'd need to find all pools, and then get their token accounts, instead of just using the main vault.
Generally, I'd recommend the multi-pool approach for your protocol. It also gives you the advantage that you don't have to write-lock same the main vault for all pools. This also makes a "proof of reserves" for pools easier - you can look at a pools internal balance, and then check if it actually holds this amount of tokens.
Daily Solana Tip 73
When learning Solana, it's crucial to understand the Account model. But when writing actual code, you'll encounter multiple relevant types: AccountInfo , AccountMeta , and your parsed Account types. What's the difference? AccountInfo is your bread and butter. That's the default high level deserialization of accounts passed to your program. It includes the pubkey, lamports, data, owner, rent information, and the signer/writer/executable flags. Next, your deserialized Account is created from the AccountInfo. data field. This data is transformed from just an array of bytes into meaningful data, such as references to other Pubkeys , u64 's, or other types. Last of all, AccountMeta is just a small structure containing a pubkey, and the writable and signer flags. Whenever you call another program, for example through a CPI, you provide a list of AccountMeta's for each account that you want to pass to that other program, defining the flags that you want to set. So to summarize: AccountInfo is what your program reads from the chain at the low level. Accounts are parsed AccountInfo. data. And AccountMeta is used to define how you want to pass accounts when calling programs. Easy isn't it?
Daily Solana Tip 74
Rust's unsafe keyword bypasses the compiler's safety checks. It allows five operations that normal Rust code doesn't: working with raw memory pointers, calling unsafe functions, accessing static mutable variables, implementing certain special traits, and accessing union fields. Each of these can potentially cause memory issues if used incorrectly.
In Solana development, you'll mainly encounter unsafe when directly converting between data types, like turning raw account data into a structured format:
unsafe { &*(
data.as
_ptr() as *const TokenAccount) }
So when do you use it? Only when necessary for performance or when handling raw data structures. Always keep unsafe blocks as small as possible, document why they're needed, and get it audited.
Never use unsafe as a shortcut around compiler errors - those errors are usually there to protect you.
As an auditor, you should always check unsafe blocks with extra care. Check if all preconditions are guaranteed before the unsafe operation executes. Verify memory alignment requirements are met for cast operations. Ensure unsafe blocks are minimal and well-encapsulated. Watch for potential integer overflows that could lead to out-of-bounds memory access!
Daily Solana Tip 75
When auditing a program, or designing your instructions as a dev, you should be aware of frontrunning attacks. The idea is that a user submits their transaction, and someone may observe the transaction before it lands, adding their own transaction to be executed just before the user's transaction. You've probably heard the term before and may intuitively think about it in relation to trading - a user places an order, and the frontrunner places an order just before the user to profit from the price move generated by the user. But that's not the only way frontrunning can work. Oftentimes, frontrunning attacks can also be found in all kinds of account initialization instructions. The user creates a transaction to initialize an account with certain settings - if vulnerable, a frontrunner could initialize the same account with different settings just before the user. If the user then keeps using the account, thinking its initialized with their settings, they may get exploited. Generally, frontrunning vectors may arise whenever someone else could execute an instruction to create an account at the same address, or manipulate outside state on which the instruction result depends. While the latter is often the case, it depends on the outcome for the user - if I can make the user get a worse execution than expected, it's a valid attack vector.
Daily Solana Tip 76
Flashloans are a very powerful primitive unique to DeFi - borrow unlimited amounts of money without any collateral, but you have to pay it back in the same transaction. (Ok the money is limited to whatever the protocol has and is willing to give you, but it's not unusual to be able to borrow millions in a flashloan.) But how does it work on Solana?
Flashloans generally work in 3 steps: Borrow, Use, Repay. All these steps have to happen within one transaction and are typically split into instructions called separately from each other - without using CPIs. You could implement flashloans with CPIs instead, though it might limit what can be done during the flashloan. Some programs explicitly disallow being called through CPI, and sometimes the additional CPI will fail due to the current maximum stack depth of 4.
So, the typical flashloan program implements 2 flashloan instructions: borrow_flashloan and repay_flashloan. (or whatever you want to call them).
Now the interesting part is this: In the borrow instruction, we require the user to pass the instructions sysvar. Using this sysvar, we are able to perform transaction introspection. This means we can look at how the current transaction is built. The borrow instruction uses this to first confirm that itself isn't called through CPI, and then it iterates through all following instruction calls in the transaction until it finds the next call to the flashloan program. It asserts that this next call is the repay instruction with the correct loan account. It checks this by looking at the instructions discriminator.
The repay instruction should also forbid being called as a CPI.
This way we can ensure that the flashloan is done as intended: borrow - use - repay, without any fishy things inbetween. In particular, we want to prevent attacks where someone could borrow - borrow - repay, or borrow borrow repay repay, or any other combination of borrows and repays that isn't borrow-use-repay. We also want to prevent things like borrow - change settings in flashloan program - repay. The repayment of the same loan should always be the next interaction with the same program - with only the usage of the flashloan in-between.
Daily Solana Tip 77
When solana accounts are created, this means that every validator in the network has to store them. And this service comes at a cost - rent. Rent is charged according to the account size. (You can find out what the rent is for 100 bytes using the command solana rent 100. It will give you the rent exempt amount). The rent exempt amount is equivalent to the rent for 2 years of storage. As the rent would be deducted from the account storing data, it would mean that at some point the account is empty and should be deleted, which could lead to all kinds of problems. That's why this rent paying system has been phased out and we use this 2-year rent exempt amount instead. If this amount is in an account, there will be no actual rent charged, and you can get the full rent deposit back once the account is closed. Nowadays we just call the deposit for rent exemption "rent".
Recently, just about 3 weeks ago, Solana activated feature CJzY83: Disable rent fees collection. Since this feature, validators actually don't collect the rent for accounts under the rent exempt limit anymore. It's not necessary anymore because there are no rent-paying accounts anymore and also any transaction that would create an account that's not rent exempt would fail. Validators were wasting processing time at the end of each epoch to try and collect rent. Therefore the term rent is now purely historical - its now literally just a fully redeemable deposit.
Daily Solana Tip 78
ever wonder what's going on with all these 'a, 'b, 'info tags that you have in your Solana programs? Especially around the Context <>, which is passed into your instructions?
These tags are called lifetimes. In short, they describe how long each value will be around, and thus can be safely referenced without causing memory issues such as a use-after-free.
Now, the Context structure has the following fields:
-
program_id
-
accounts
-
remaining_accounts
-
bumps
and the first three are actually references: essentially three pointers to the program_id, accounts , and remaining_accounts.
Lifetimes declare that a pointer's target data lives for this relative amount of time. Here's an example:
pub program_id: &'a Pubkey,
means that program_id is a pointer to a Pubkey , and the Pubkey it points to will be around for the lifetime 'a.
As you can tell, we're not explicitly saying what the lifetime of 'a means. Lifetimes are always relative. We're not declaring anywhere that 'a is created at the beginning of the program and deleted at the end. No, we are just saying that it exists.
So how are they useful? They become useful once we introduce relationships.
If you look closely at the following code:
pub fn process_ix<'a, 'b, 'c: 'info, 'info>(
ctx: &'a Context<'a, 'b, 'c, 'info,
ProcessIx<'info>>,
instruction_data: InstructionData,
) -> Result<()> {
you'll notice the declaration 'c: 'info in the first line.
This means: 'c must live at least as long as 'info
As 'c is referring to the reference to all remaining_accounts and 'info is the lifetime of AccountInfos this makes intuitive sense. If the AccountInfo lifetime would expire before before 'c , our remaining_accounts might try to access invalid data.
By the way, 'info is the same lifetime we use for our other AccountInfos when defining our derive(Accounts) struct.
And that's all there is to it. Hope you understand now what lifetimes are and this mess of < 'a, 'b, 'c, 'info, ....
makes more sense to you!
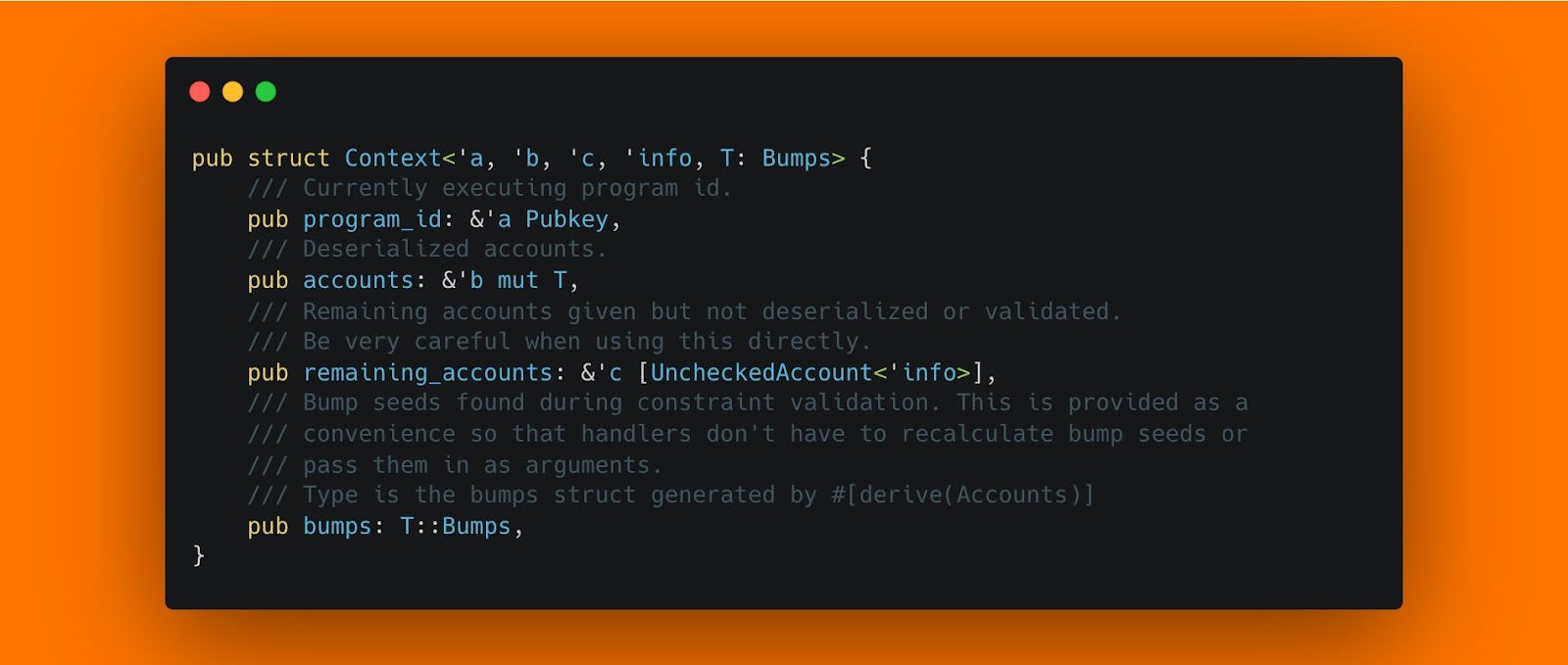
Daily Solana Tip 79
Let'd dive into the cryptography behind Solana keys today. Solana uses Ed25519, which is based on the Edwards-curve Digital Signature Algorithm (EdDSA) and uses a specific prime number: 2^255-19. Curve means: Elliptic Curve Cryptography.
A brief primer:
Elliptic Curves have the fun property that if you choose two points on the curve and draw a line through them, the line will cross the curve in a third spot. Now you can reflect this spot on the x-axis to gain the sum of your two selected points within a finite field. (think of a finite field as a fenced off version of math where instead of all numbers you use a cycling set of values. For example the alphabet. instead of numbers, you can use A-Z. Adding A+B = C, and adding Y+B = A. But instead of the alphabet we do our math "on the curve". We do this because we have certain properties within this subset of mathematics). Now instead of just adding random numbers on the curve, we can add the same number to itself by using the tangent on that point on the curve. Wherever the tangent line hits the curve, we have our sum of two points. Now The beauty here is that its quite easy to calculate kP (P is the point, k is a scalar), so just doing this over and over again for some Point, but it's near impossible to do the inverse - when we have the result of kP, and also P, we can't really find out what k used to be. Therefore k is kinda private - our private key, and kP is our public key, which is directly constructed from the private key.
I know that's a lot of gibberish, but what this means is:
-
Your private key is a secret scalar which can be used to calculate your public key
-
Your public key is on the curve, while your private key is just a random number
-
PDAs are defined as "Pubkeys" that are not on the curve - therefore they can't have a Private key. No scalar can be used to find a point thats not on the curve
if you're more interested in how this work, I can recommend the following resource:
Daily Solana Tip 80
There's one extremely simple but often overlooked concept that distinguishes great code from bad code.
It's naming.
And I don't mean the struggle between naming your project dump dot run or limp dot fun.
I mean naming variables, structures, instructions, enums, types, and modules in your code.
Some of it might be obvious to you - naming all your variables a and b is obviously going to be confusing. But let me surprise you: Clear names like withdraw or deposit can be equally as opaque. Is it the user depositing? Are they depositing into their account, or LPing? Is it the admin withdrawing fees? Or the user withdrawing their stake? ...
And don't get me started on ' owner '!
You will often not notice your own bad naming habits as a dev - your names will seem clear to yourself. But once you bring in another dev or an auditor, they will struggle with your code.
Struggle means - having to look up implementations every time because they're not sure what that name meant. Forgetting what variable to use because the name isn't logical. Just slowing down their workflow, which compounds over time.
Simple fix: Name your things well. Easier said than done. Let me try to guide you through it.
Let's start with state accounts, such as the account that will store the individual user's data. Normally you want to go with a capitalized noun here, describing the object. For example: User. Keep it simple, but clear what this object stores. Other good account names are Global for your global program state, or Pool for a pool. A bad name imo is Config , as it's unclear what it configures - ProgramConfig , FeeConfig , or GlobalConfig might be better.
Next, your instructions. This is important to get right. In my experience, the most clear instruction names follow the schema subject-verb-object. Subject is the authorized party who can execute this instruction. Verb is what the instruction does. Object is what this is done to.
Some examples: user_withdraw_lp. admin_collect_fees. public_init_user. public_crank_market. If an instruction is public, you may instead leave out the prefix public_. These instruction names make it instantly clear what they do, and who can call them.
The bad version of those would be: withdraw , withdraw_fees , new_user , crank. Imagine the same program with the same 4 instructions, one of them using the first 4 names, the other using the second version. One of the two immediately feels sloppy compared to the other.
Next, your input account variables. What I mean here is what you name the account variable that each input account is assigned to. Those live in your anchor instruction definition structs ( derive(Accounts) ). Just use descriptive names here. Call the signer authority or payer ( payer only when they pay for fees like rent). Just don't use owner. Call your mints mint , and not token. This part should be easy.
Next, variables, or fields within structures/accounts. You want them to be clear as well, and the type should be self evident. Duh. Let's take, say, Order.locked. That would be an extremely bad name. locked - is it going to be a bool , an enum , an a mount/u64? What's locked? Is it about funds or the Order as a whole? A better name could be Order.locked_fee_amount. It's clear that it's probably going to be a number, and it's probably about fees associated with this order.
When creating names for variables that hold numbers - sometimes you can come up with better names than "amount". For example: fee_bps : it's clear that the amount should be in basis points. Or fee_lamports : It's clear that we expect an amount of lamports (sol). (You could also create custom types for these instead of using u64 ).
The last important thing to name is your enums.
When you define a State enum for one of your accounts, each state name should clearly convey its own meaning. For example, lets take a governance proposal. A proposal could have been proposed, and now be live voting. In that case State::Voting would be more appropriate than State::Proposed , as Voting implies that it has been proposed, and also gives us the information that voting is ongoing. An even worse alternative may be State::Live or something like that. The developer might have meant "The proposal is now live and being voted on". But the state itself doesn't imply that directly. It could also mean that the proposal is live in the sense of - it has been approved and implemented.
That's it. Name your shit well. Please
Daily Solana Tip 81
When you encounter an open source Solana program and you're considering to deposit your hard-earned money, it's important to trust the developers.
Yea, we're in crypto, yea, don't trust, but verify etc.. but even when they have 20 audits on their code, and their code looks clean to you, unfortunately it is quite easy for a seasoned Solana dev to hide a backdoor. (Something that would allow them to rug the project's funds at any time.)
Actually, by default most Solana programs have a "backdoor", which is the upgrade authority. Though this can be publicly locked down in a multisig or DAO so that users have assurance that the program won't get upgraded without some lead notice. But there's other kinds of backdoors.
One of them is through fees - admins just suddenly updating fees to 100% (or even more if the code somehow allows it).
Another backdoor mechanism is to add very sneaky bugs into the public code, or to just hide backdoor code in-between test modules, or wherever. Look up the "underhanded c contest" to get an idea of this.
Another particularly sneaky technique is to create a version of a program that creates special backdoor accounts, initialize them, and then upgrade the program to a version where these accounts aren't mentioned at all. A reviewer would have to check the chain state and find these accounts before they can approve the code. We can also hide code in dependencies and god knows where. For a real-world example of how build-time dependency code can be exploited, see our post on how we hacked Solana verified builds.
All I'm saying is: If a dev of a program you use really wants to rug you, they will find a way. Best assurance you can have of no backdoors is:
-
non upgradeable, or strict multisig
-
program deployed to completely fresh keypair. All prior versions have been checked for the following
-
no untrusted dependencies
-
audited with backdoors in mind
-
code normalized and produces same build (stripped of comments, tests, anything unnecessary)
-
admin interventions limited in capability (e.g. max protocol fee const defined that even admin can't go over)
-
devs doxxed
-
formally verified
As a dev you can instill more trust in your own program by doing more of the above.
Daily Solana Tip 82
When writing solana programs, you've certainly encountered macros, especially if you've worked with Anchor. For example, logging in rust is done with the println! macro, or with msg! in solana_program. But there's other macros too, for example #[derive(Accounts)] , #[account] , declare_id!() , or your constraints like #[account(mut)]. So first of all: what are macros? Simply said - macros are shortcuts to generate code for you when the program compiles. They're generating repeatable code for you so that you don't have to write it out every time. The difference to functions is that macros are created at compile time and can incorporate your syntax, such as names of variables. As you might have noticed, there are different kinds of macros: - declarative macros: Simple pattern-matching macros, where you match against some syntax pattern and generate code from that - procedural macros: Like functions that will operate on AST TokenStream objects and turn it into code. Needs extra dependencies - derive macros: automatically implement traits for structs and enums, e.g. #[derive(Accounts)] - attribute macros: apply certain attributes to items. E.g. #[account(mut)] Now the fun part: You don't just have to rely on Anchor's provided macros. You can implement your own! Starting with declarative macros, you may want to build your own debugging function with enhanced information like currently executing instruction and line. Or you can build a CU logging wrapper. You can also build your own assertion macros. Using procedural macros (or also declarative), you could build shortcuts for common things like transfers, fee calculations, safe math and so on. You could implement your own derive macros to add to your Accounts structs - for example to add validation functions, or for your #[account] struct to generate an account size calculation. Using attribute macros you could create your own constraints. For example you could build an admin_only macro for your instructions. Overall, once you're comfortable with the odd syntax you need to create macros, they turn out to be very useful. Oftentimes bugs arise from copy-paste errors because developers copy their fee calculation logic 10 times throughout their program, or they have copied the same token transfer logic 20 times. One of the best uses for macros is to create one sound implementation that you can then use anywhere in your program. Next time you find yourself repeating a lot of code, think about using a macro instead! As an auditor, you should know about the cargo-expand tool. (cargo install cargo-expand), and then you can use cargo expand in your work directory. This tool will roll out all macros and generate the code, so that you can review the actual generated code if needed.
Daily Solana Tip 83
One common bug in Solana programs is forgetting to reload accounts after CPIs, or to write accounts before CPI.
What does that mean? Typically your programs, and especially Anchor work like this:
At the beginning of your instruction, deserialize input accounts and copy the deserialized version of them onto the stack (or heap with Box ).
Then you do all your business logic using the working copy on the stack, and only at the end of the transaction, you write your changes to the chain before the instruction ends.
Now when you perform a CPI, the called program will not receive the working copy of your accounts. They receive the account state that is onchain.
When the called program finishes, it may write data to its own accounts. Now when your caller program picks up again, it will not read the chain state and overwrite the local working copies of its accounts by default. If you want this to happen, you need to actively reload the accounts.
Remember: Only the owner program can write to accounts. Your program can write to its own accounts, and the other program can write to their accounts.
Therefore, a simple rule of action for you:
-
When your program writes account data and then calls another program with the modified accounts, so that the callee will read from the accounts, make sure to first serialize your writes to the chain, so that the changes arrive at the callee
-
When your program reads account data from accounts that belong to another program after it calls another program, make sure to reload the accounts so that changes done during the CPI are reflected in your working copy
Daily Solana Tip 84
Oftentimes your program design will involve well defined states, even if you don't actually define them. For example, a launchpad program that has 3 phases: initialization, where the launch is configured, then the phase where funds are collected from anyone who wants to participate, and the last phase where the token is launched, or alternatively where the launch has failed to collect enough funds. You could build this without a state variable just by checking variables like the total funds collected and the current time, and the defined launch time window. But such code quickly becomes quite messy, it depends on many manual checks and that's simply error-prone. So instead you should define a state variable. You can do this by creating an enum, and defining each state, such as {Initialized, Collecting, Launched, Failed} for our launch.
Now, to really take advantage of your newly defined state, you should create explicit state transition methods defined directly on the enum as Impl's! Each state transition function should only perform the state transition if all conditions are met, and then define the next state accordingly.
Did you know that Rust enums can have arguments? For example, you can define your Launched state as Launched { committed: u64 } , directly encoding a variable that only exists in this state.
In addition to state transition functions, you can now also define conditional checks on your enum, and use one of Rusts best features: match statements!
Using state variables with clear transition functions and match statements in your instruction logic is a cheat code for writing safe solana code. Actually, many bugs arise from unclear state and state transitions, and using such a system pedantically can plug this hole completely.
Daily Solana Tip 85
When you define your Solana program, you need to define an entrypoint. This is the place in the code where the SVM will begin program execution. Programs generally work similar to those books where you read a page and it tells you which page you should jump to next, depending on the story line you choose. The entrypoint is the first page that you start reading from.
In a native program, you define it like this:
#[cfg(not(feature = "no-entrypoint"))]
use solana_program::entrypoint;
#[cfg(not(feature = "no-entrypoint"))]
entrypoint!(process_instruction);
where process_instruction is your entrypoint function which takes the arguments program_id: &Pubkey, accounts: &[AccountInfo], instruction_data: &[u8]
When you include another solana program as a dependency you should include it using the no-entrypoint feature, this way you won't have two entrypoints defined. That's what this feature definition above is for.
When you create an anchor program, the entrypoint is defined for you by the program macro.
But how does the runtime know what the entrypoint will be? As programs are ELF files, you might think that they will simply use the Elf entrypoint. But that's not the case. Instead, a function with the key 0x71E3CF81 is registered, which is the murmur3 hash of the string " entrypoint ", and this function is used as the entrypoint. That's all there is to it!
Daily Solana Tip 86
Cryptography often requires quite computationally expensive operations. That's why Solana provides multiple cryptographic primitives as precompiles or syscalls onchain. Let's take a look at what these cryptographic functions are specifically and what we can do with them!
First of all Solana has 3 relevant native programs:
Ed25519SigVerify111111111111111111111111111 , which provides signature verification on the ed25519 curve, the native solana curve
KeccakSecp256k11111111111111111111111111111 , which provides signature verification on Ethereum and Bitcoins native ECDSA curve, and
Secp256r1SigVerify1111111111111111111111111 , which provides signature verification for signatures generated by many hardware security keys.
Next, Solana provides many relevant syscalls. Just for hashing we have syscalls to calculate sha256, keccak256, blake3, and poseidon hashes.
In addition to that we have some special operations like secp256k1_recover to recover a key from a signature on ECDSA, and multiple specialized operations for ed25519 as well.
Furthermore, there are special syscalls for alt_bn128 calculations - another elliptic curve especially useful for Zero Knowledge implementations. These include standard ops like multiplication, addition, but also alt bn128 compression, which is another trick to reduce compute and space costs in ZK calculations.
And to round it off, we have a special syscall for big mod exp, another common operation used in many cryptographic systems.
Now that we have the plain facts - what can we actually do with all this? First of all, we can verify digital signatures on-chain. This can be used to verify identities, or another layer of transactions. Through specialized support for ECDSA, we can build primitives that directly work with Ethereum and Bitcoin, such as cross chain bridges! Through altbn128 support and efficient hashing functions we can build various Zero Knowledge protocols, verifying proofs onchain. Secp256r1 verification allows us to directly support hardware security keys. Different cryptographic systems come to mind, like zk rollups, homomorphic encryption, verifiable random functions, or custom privacy protocols.
Daily Solana Tip 87
What actually happens when you send a transaction from your wallet on Solana?
First of all, some application constructs the transaction for you, and asks you to sign it. At this point the transaction reads something like "call program A with data asdf and accounts X(writeable, signer) Y(writeable), Z(read only) then call program B with data qwerty and accounts (X writeable, Signer), W(read only), U(writeable)". Even though it has indicated signers, there is no signature until you sign it with your private key.
Once signed, the transaction is fully serialized together with the message and signature(s), and sent on its way. But where? To an RPC node. The RPC node acts as a gateway to the blockchain. It typically will check the transaction for correctness for you, and then the node will directly forward the transaction to the current or upcoming leader, which is the validator who's turn it is to create blocks right now. The leader receives the transaction through its Transaction Processing unit and then processes it.
Now, during high congestion times, solana experiences a lot of spam and needs to prioritize. That's why there are some other methods to send your transaction on its way. First of all, sending directly to the leader - with some custom code, you could just skip the RPC and send your transaction directly to the leader, though you will contribute to network spam this way. As a resistance, Solana introduces SWQoS (stake weighted quality of service) which lets the leader prioritize transactions that were submitted through an established channel coming from staked validators.
Now why should you know about this stuff?
First of all, you can optimize your transaction landing capabilities: Select an RPC with a strong SWQoS node, giving you better chances of landing your transactions. Second of all, you should realize that by default, your transaction doesn't go directly to the blockchain - instead it's first picked up by an RPC. This means if you send your transactions to a malicious RPC, they have access to your transaction before it's submitted onchain, similar to a mempool. They could for example bundle your transaction with buys and sells as a sandwich, giving you worse execution. (for bundling they don't need to change your signature, they just add two more of their own transactions that shall execute together with yours!) For devs and auditors this means that you should be aware that frontrunning risks are very real. Expect that instructions submitted to your program can be frontrun and design them in such a way to minimize negative impacts to users.
Daily Solana Tip 88
Some programs need to support arbitrary invokes - which means that the user can supply an arbitrary other program that your program will then call. For example, this pattern is used in multisig and DAO proposals. It can also be used in some types of flashloans, or in infrastructure programs like bridges, layers, or virtual machines. But how can you let your program invoke, or even invoke_signed an arbitrary other program safely?
First of all, we need to distinguish between invoke and invoke_signed. Basically they are the same, but invoke_signed can add new "signatures" for PDAs to the call. What's important to know is that both will pass through signatures that they have received from the parent call. So if I call program A, signing for my wallet W, and A calls B, B will also receive a signature for my wallet W, both with invoke and invoke_signed.
So how can a program make sure that the callee doesn't do anything bad? First of all "doing something bad" basically translates to unexpectedly changing account data in Solana terms. That's all programs do after all. Therefore the best tool we have is to not pass accounts that we don't want to be changed into the CPI as account infos. However, sometimes you have to pass accounts into the CPI. Maybe the callee might need them, or you need to pass the accounts to keep the runtime's balance checks happy. Therefore, the second best tool in your toolbox: marking accounts as read-only. By marking accounts as read-only, the caller can ensure that critical accounts are not changed by the callee.
Next, there is another important check to do: When a user can supply any account for you to call, they may also supply your own program, creating a self-reentrancy scenario. Often it is advisable to forbid self-reentrancy calls, or limit them to certain instructions by checking the instruction data of the proposed call before executing it.
Daily Solana Tip 89
Let's investigate how Solana transactions are serialized in detail!
Solana transactions consist of two parts: A signature array, and the transaction message.
All arrays in the transaction serialization use short vecs, which means that the array length is serialized into just one to three bytes, and normally just one byte, as long as the array length is under 0x7f.
The signature array simply stores 64 byte signatures. Easy. The Message is what contains our interesting transaction data, let's dive in!
First of all, there are two types of messages: Version 0 and Legacy. (idk who comes up with these names). Version 0 supports cool stuff like Address lookup tables. But legacy is our bread and butter. It consists of 3 parts: The message header, another short vec of Account Addresses(Pubkeys), a recent blockhash, and another short vec of Instructions.
The message header consists of just 3 bytes, and these are offsets in the following Account Address vector: The first offset splits the whole vector into two parts: all addresses before the offset must be signers, and all after must not be signers. Each of the remaining two offsets in the Header split one of these halves into further halves, effectively quartering the array. Their purpose is to split the signers and non-signers into writeable signers, read only signers, writeable non-signers, and read only non-signers. This is a pretty clever serialization trick: Using just three index bytes and by sorting the keys, we know for every single key if it's a signer, writeable, or readonly. Next, a recent blockhash serves as a proof of timeliness for our transaction, followed by an array of instructions. Each instruction is split into three parts: The index of the program id that the instruction calls, an array of accounts the instruction wants to use, encoded as indexes, and in the end the instruction call data to go with our call.
All of the account indexes simply refer to an index in the account list. This means two users who call the same instruction in different transactions may have different indexes in their instructions, as it fully depends on the sorting of the Pubkeys.
What can we learn from this? First of all, adding additional accounts to an instruction only adds one byte to the transaction if the account address was already in any transaction in the same transaction.
Also, account properties like being writeable, readable or signed are shared across the whole Transaction!
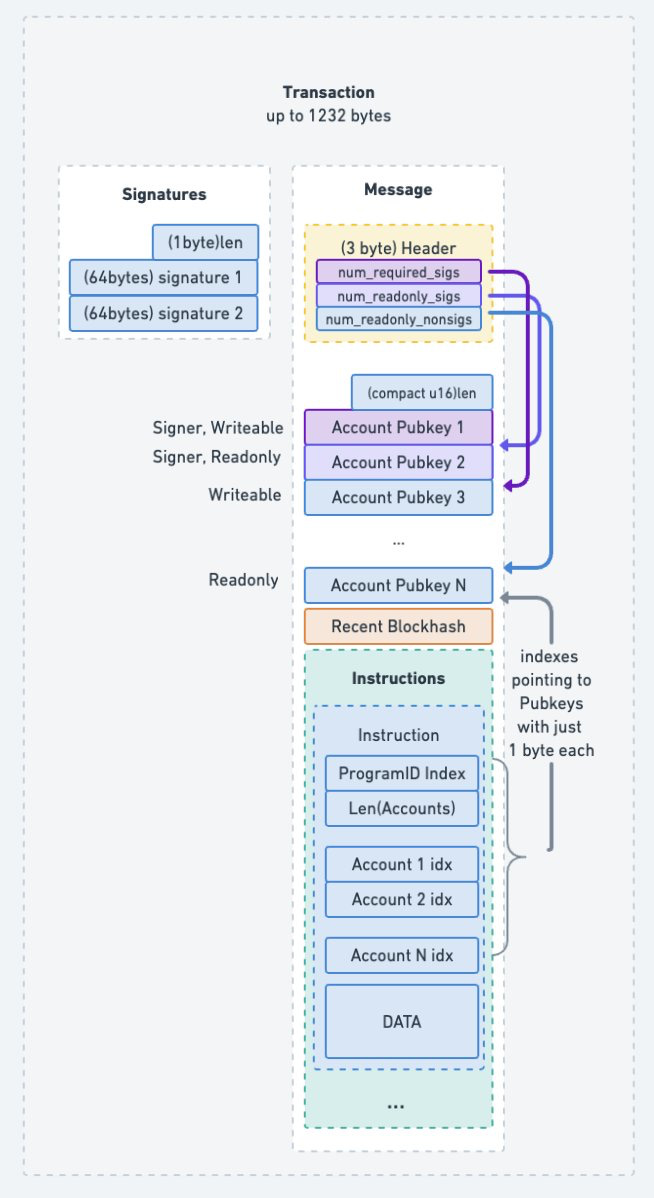
Daily Solana Tip 90
You knew that you can write Solana programs in Rust, but did you know you could write them in C as well? There even are some official examples by solana labs on how to write your Solana program in C! You just need to use the C solana_sdk.h, define an entrypoint, deserialize the input parameters using the sdk's sol_deserialize function, and then do what you want! (And its not even that obscure - If I remember correctly, mayanswap implemented their Solana program in C).
So, as you can see, writing your Solana contracts in C isn't hard at all. However, let me one-up this: You can write your contracts in Assembly! I've stolen the attached example from @deanmlittle, it implements the fibonacci sequence on Solana. What you notice is that it's pretty easy too - you just need to know the deserialization format and you syscalls. If you want to build your own assembly programs, use deans https://github.com/deanmlittle/sbpf to try it out.
Now what's the point of all this? If not just for the low level learning experience, you may want to try writing programs in C and Assembly for optimization. Anchor programs are known for being quite bloated, in program size as well as in CU usage. Building your programs at the lowest level keeps them absolutely tiny and extremely efficient. Using inline asm, you can also write your program in rust, but optimize critical functions using Assembly.
Daily Solana Tip 91
What happens when you pass the same account twice into an instruction?
First of all, this is not an issue when the account is passed as readonly twice - the state of it won't change, so there's nothing to worry about. However, it may become an issue when you're mutating the account, i.e. passing it as writeable. So what if you pass an account twice, once as read-only, and once as writeable? Well, in fact you'll be passing that account once as writeable into your transaction, and referencing it twice. To understand what happens then, you need to understand when data is read from an account, and when it is written.
Reading happens when the account_info is deserialized into an account, and writing happens when an account is serialized into an account_info. Normally, accounts are read at the beginning of an instruction and written at the end of an instruction. This means that internally, the instruction will start working with the same data, mutating them in different ways (or not mutating them), and then writing the resulting account states one by one. As we are writing one by one, this means that the last write will be the one that will be on chain. When an account is passed as readable to anchor, it will not be serialized to the chain at the end of the instruction, which means when we pass an account as writeable and readable to an anchor program, the written value will prevail.
When we pass an account as writeable twice to anchor, the last write will prevail, and writes happen in order of appearance in the Account struct.
Next is another interesting version: What if the same account is passed to anchor's init twice in one instruction? Simple: The instruction will fail with an account already in use error, because the first initialization will go through and the second will try to allocate/assign the same account, which will fail. So... what if we use init_if_needed? The second init_if_needed call will fail with a discriminator check failure. But why? doesn't the first init_if_needed set the right discriminator? The answer is: only at the end of the transaction when the account data is written to the chain! At the time that the second init_if_needed is reached, the account is allocated, so the init part is skipped, and then regular account checks are done. The account discriminator will be just 0 bytes at this time though, which means the discriminator check will fail. So, you don't really have to worry about duplicate accounts in your inits!
Daily Solana Tip 92
I've done a couple posts about ways to reduce CU usage, but never really talked about the point of it. CU means Compute Units - it's a measure of how long a computer needs to execute your program. Basically, it's the same concept as gas in Ethereum. When your program is executed, this means that the current leader will run it, produce some results, and then every validator will also run the same program to validate the leader's results. What's interesting about Solana is that we don't directly charge for CU. Instead, Solana charges a base fee of 5000 lamports per signature, and you get a budget of 200k CUs for your instruction. Should you exceed that limit, your instruction will fail. However, you can ask for a different (higher or lower) compute budget using the ComputeBudget program. In the same step, you can also provide a Priority fee, which is how much you are willing to pay per compute unit in addition to the signature costs.
This begs for some questions: Why would someone pay priority fees when it's voluntary? And why would someone request less than 200000 compute units?
The answer to both of those questions is: to improve execution of your transactions. You can pay priority fees - as the name betrays - to prioritize your transactions over other transactions. It's not dissimilar to a little bribe. The request of a lower amount of compute units is supposed to help the leaders scheduler. It's easier to schedule a 2 day vacation than a 4 week vacation, so you're hoping the scheduler will include your transaction earlier because it was easier to schedule. Another aspect of it: Whenever you request compute units and pay for them, you are paying for the whole requested allotment. So if you request 200000 CUs, pay a high priority fee on that, but only use 10000 CUs, you just overpaid 190k CUs for nothing. So what you want to do is measure the CU usage of your instructions and request only that amount.
You should be aware that CU usage for the same instruction can fluctuate - typically due to PDAs. Because PDAs find the first bump that results in a hash that's not on the curve, sometimes it can require multiple tries to find that bump - resulting in a higher CU cost for the transaction.
For a reference of CU costs of various syscalls, check the screenshot!
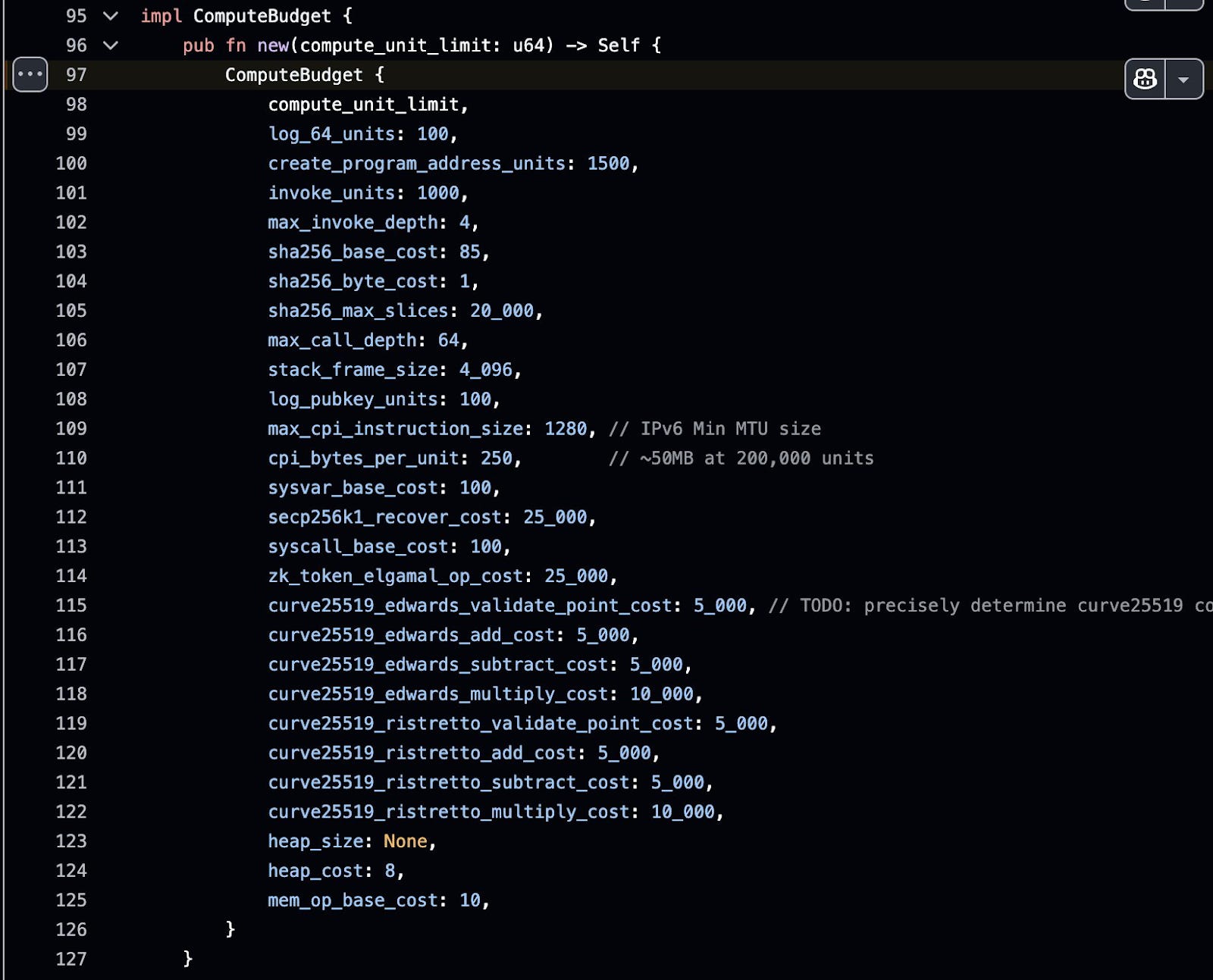
Daily Solana Tip 93
When you're writing Solana programs you'll probably use u64 a lot. However, you'll use it for different things: amount of Lamports, amount of tokens, slot number, and so on.
This leads to situations where you implement helper functions that were supposed to be used for Lamports, but because they take a u64 they might be used for token amounts or slots. Generally it can be advisable to introduce type safety into your program. For example, you could introduce a Lamports type, and a TokenBalance type, and ensure they are never intermixed. Then you could also implement functions on those types, such as apply_fee for example.
When implementing types in rust, you may want to use
type Lamports = u64;
but this will be useless as it doesn't enforce type safety. If you really want to be safe, you'd need to use a struct type like
struct Lamports(u64);
But then you can implement functions on that struct as you are used to! You can access the value using .0, or by implementing a custom accessor function.
Daily Solana Tip 94
Recently I came across the following check in a Solana program. The instruction took another account as an input, and went on to save the account address for later use after passing the following check:
if *ctx.accounts.other_program_account.owner != other_program::ID {
return Err(Error::InvalidAddress.into());
}
other_program was a related program with only one Account type.
The assumption was: if that account belongs to other_program , it will have that one Account type, and we can later use it as such.
However, I found a way to completely circumvent this assumption: The transient owner attack. On solana, you can assign system accounts that you can sign for to any other program. This means I can create an account and simply assign it to be owned by other_program. This will bypass this simple check, but I can't really do anything with the account after it's owned by that program right?
Well that's where the transience comes in: When I assign an account to another program and don't deposit any lamports in the account, the assignment will persist until the end of my transaction, but after that, the account will be deleted and automatically reassigned to the system program.
This means that I can assign an account to other_program , call the vulnerable instruction, which will pass the check and save the account address, and then in another transaction I can assign the account to a different program, and put fake data in it.
(Honestly though this attack is rarely useful and applicable but it's neat)
Daily Solana Tip 95
One of your most effective tools against bugs is testing. But testing is hard, especially on Solana where we have a tradition of difficult DevEx and chewing glass. But I want to help you write some tests today!
There's five main testing approaches you should know about in the Solana ecosystem (and I'm probably missing some more):
Rust Unit Tests:
The very first and easiest to start with testing methods is to just use Rust unit tests. These tests are supposed to test individual functions, or small sequences, and not even entire instructions. You can add them by creating a module like follows, adding tests that fail on panics:
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn my_test() { assert_eq!(some_function(4,5), 20))}
}
Use this approach to test individual helper functions and utilities in your program.
Solana Program Test (Cargo Test SBF):
This is the OG solana testing toolkit. You write your tests in rust by including the solana-program-test crate, and then creating a test module, in which you define multiple test cases. In each test, you create a ProgramTest instance, which serves as your blockchain and RPC stand-in. The difference to unit tests is that the ProgramTest instance deploys your program in a SBPF VM, and you can actually call the full instructions and check the resulting account states. The ergonomics are similar to unit tests, but you'll have to write some helper functions to get your program into the desired state before testing. (Such as creating mints, airdropping tokens, initializing the program state, etc.)
Anchor Tests:
Anchor provides a build in script for running tests using anchor test, which uses typescript and mocha to write your tests. You define your tests in typescript much like you'd write a client for your program in typescript. It's a comfortable environment to run simple tests. By default, this will use a local solana-test-validator instance. This means that for your tests, a local validator is spun up, which has its own advantages and disadvantages. My favorite thing is that you can run anchor test --detach, which keeps the validator running after the test suite, and then you can look at the test transactions using any solana explorer. Writing your tests in typescript has many advantages: You can easily define pre- and post- test routines, you can use typescript libraries, and you're testing like most integrations will probably use your program.
LiteSVM:
The above testing frameworks are sometimes limited in some ways - for example, spinning up a whole validator might just be too slow for you when you want to run big test suites. Sometimes you want to test a very specific state, or run multiple tests starting from a specific state. You may want special abilities in your test blockchain instance. Abilities like changing account data, moving the system clock forward or backward, or even disabling signature verification, so that you can sign for specific accounts that you don't have a key for in your test environment.
These features aren't really available with the above test frameworks. LiteSVM however is built to do exactly that. You can use LiteSVM in Rust, TS or even Python (solders) to write tests with these special abilities. LiteSVM creates a testing optimized Solana VM instead of a validator, which makes it pretty quick compared to the alternatives. Its API is pretty simple too!
Mollusk:
Mollusk is a new addition to Solana's testing landscape, provided directly by Anza. Internally, it's another super light testing harness, which does not rely on any of the validators large components. It creates a small program cache, transaction context and invoke context when processing instructions, and then directly executes the program using the BPF Loader. As it is so light, it offers just four main API methods: process_instruction , process_and_validate_instruction , and the same two methods but for a instruction_chain, instead of a single instruction.
Instead of writing many assertions or require statements, mollusk lets you provide an array of Checks, which are predefined configurable common require statements, such as checking the program result, account balances, or account data. It also provides a built-in compute unit benchmarking module, and support for test fixtures.
As a dev I encourage you to try out all these options, and see what you like to use. It's more important to write tests than to write them in the most efficient framework, and I think you should use whichever framework will help you write more and better tests.
Auditors should be familiar with all of those as well. Often you may want to test something in an audit and it's most convenient to add another test to whatever test framework the client is already using. That's why you should get comfortable with writing a simple test in all of them!
Daily Solana Tip 96
Yesterday I talked about testing Solana programs. Today I want to talk about a special type of testing: Fuzzing (or fuzz testing).
What's fuzzing? In short, instead of writing out countless tests manually, you create an automated testing setup which generates random inputs for your program and programmatically verifies that the program executes correctly. For example, in the world of traditional software you could automatically generate random image files and try to open them with photoshop, observing if the program crashes.
In the context of solana programs this means that you automatically generate either function calls for unit tests, or instruction calls for program tests, or instruction call sequences, and throw them at your program. That part isn't so hard. You can easily generate millions of instructions for random combinations of deposit amounts and signer keypairs for your program. Because there are so many possible combinations of inputs and sequences, the art is in creating test cases that actually test relevant things.
Solana programs take two inputs: Instruction data and accounts.
For instruction data, you can generate varied parameter values while ensuring they meet your program's constraints. The real challenge is with accounts - you need to create valid account structures with varied ownership patterns, balances, and data layouts.
Tools like Trident provide specialized fuzzing for Solana, automating the generation of test cases targeting potential vulnerabilities. For Rust-based programs, LibFuzzer integration allows for sophisticated mutation-based testing without running the full Solana runtime.
The most effective approach combines coverage-guided fuzzing (prioritizing inputs that trigger untested code paths) with transaction sequence fuzzing (testing chains of instructions that mirror real user interactions). This helps uncover not just crashes but subtle logical errors and economic attack vectors.
Ready to start? Begin by creating a simple test harness that generates randomized instruction data for your most critical functions. Start small with just one instruction type, then expand the scope. Try Trident for a more comprehensive framework, or experiment with LibFuzzer if you're comfortable with Rust FFI. Even running basic fuzzing overnight can uncover edge cases your manual tests missed – potentially saving you from a costly exploit in production.
Daily Solana Tip 97
Did you know solana is working on a new toolkit for developers called mucho?
This toolkit will include everything you need to develop and test your Solana programs: It comes with the solana cli and agave tool suite, the mucho cli, rust, anchor, a fuzz testing framework and a code coverage tool for solana programs.
In its core, it provides its own cli, the mucho cli with the following features:
-
manage your solana development tooling
-
run a solana test validator
-
inspect transactions, accounts, etc.
-
support for a new Solana.toml file
-
building and deploying solana programs
-
token tools like creating minting and transfer
-
viewing balances
-
and more to come...
What makes mucho special is the unified developer experience. Instead of juggling multiple tools with different interfaces, mucho provides a consistent workflow for the entire development lifecycle. The integrated fuzz testing and code coverage tools are particularly valuable for writing secure programs!
To get started, just install mucho using npx mucho@latest install , and then use. mucho --help . to learn about particular commands. For example, using mucho inspect, you can just provide a pubkey, transaction signature or block number and it will automatically give you the correct information, just like a web explorer.
Fair warning: Mucho is still very much in active development - expect bugs and rough edges. Consider it an alpha version for now. I've hit some bugs myself, but the dev team is actively fixing issues. Play around with it for side projects, but maybe hold off on using it for production work until it stabilizes. Check the GitHub issues if something breaks - chances are someone's already reported it.
Daily Solana Tip 98
When building and auditing Solana programs, it's really important to understand CPI in-depth. So today I want to talk about some of the restrictions that exist when performing CPI calls. I've talked about most of these before in separate threads, but I think it's good to have them collected together. First of all, CPI means Cross-Program-Invocation. This means that one program calls another. Each CPI takes the program address to call, accounts to call with, instructions, and signer seeds. Did you know that signer seeds have limits per PDA? Each PDA can have a max of 16 seeds with each seed being at most 32 bytes long. Currently, the program that we want to call through CPI has to be passed at the top level to the calling instruction within the transaction (but this might change). Every account that will be touched in the CPI has to also exist in the top level transaction, which automatically limits the number of accounts we can perform a CPI with. But with versioned transactions and Address Lookup Tables that number is pretty high. Though the account lock limit for transaction is still at 64. By doing a CPI, we can add virtual signers to the transactions - signing for PDAs that are derived from the caller program. We add them by providing signer seeds to the call. Currently, there is a maximum call depth of 4 for CPI calls. This means our program A can call B which can call C which can call D, but no further. However, there are talks to increase this limit soon. Another limit that you'll encounter for CPIs is that during CPI calls, accounts can increase their size by 10kb at most. The next limitation is your compute budget - it's not a direct limitation to a specific CPI, but your transaction has a shared CU limit of 1.4M CU for the whole transaction (or 200k by default - you need the CU budget program to unlock the 1.4M). But in theory, when your instruction uses up 1.4M CU before the CPI, the CPI will fail. Also, be careful when performing direct Lamport Access (adding and subtracting lamports directly) and then doing a CPI afterwards. You'll need to include all account infos with changed lamports, or none of them, otherwise the runtime will complain. So include them even when the called program doesn't actually use them! The runtime keeps an eye out for you. It also makes sure that you don't perform reentrancy, which means that you can't do a A->B->A CPI call loop. A->A is fine though. Also, there's an overall cap on the number of CPIs you can do. This is called the trace length, and is capped at 64, which means you can do at most 63 CPIs in your transactions! This bound includes all instructions in your transaction though! I think that's all you need to know for CPI limitations!
Daily Solana Tip 99
Many protocols launch their Solana program without disclosing their source code. They might believe that this protects them from hackers and their competition, but there are a few ways to get information from a closed source program.
First, we can dump a program binary with
_solana program dump <PROGRAM_ID> _program[dot]so
and disassemble it with
llvm-objdump --print-imm-hex --source --disassemble program[dot]so
Running strings program[dot]so will also give us some hints: all the strings within the binary, which normally includes all instruction names, and debug info like error messages or enum names can be found. That's a great start for understanding what a program does!
Next, we want to get the IDL. Sometimes it will be available onchain, (use anchor idl fetch). Sometimes the devs share it in their docs. Sometimes there's a public SDK that contains the IDL. Sometimes you can look at their website app's frontend source code to find the IDL embedded within. (I have a thread about this trick) If we're not lucky with any of those options, we'll have to manually reconstruct it.
We can understand a lot from onchain program logs, traces, and accounts. You can load as many instructions calling the program as you can find, and then programmatically list all CPIs that the program does in which instruction. Next, you can identify which instructions take what accounts, and what accounts are shared across different instructions. A great approach is to use the app yourself, and on each interaction noting down which onchain instructions were triggered with which accounts and data. Just reading the program logs will often give you a lot of information too !
Instead of using the chain and explorer, you may want to use Dune instead. It lets you build more sophisticated queries, for example to only show you instructions with certain instruction discriminators.
Sometimes, you can find a devnet deployment of a program with additional debug information, like more logging! This can be a real cheat code, but there's no guarantee the mainnet program behaves exactly the same.
Once you've exhausted your easy options, you can pull up the artillery - using reverse engineering tools like ghidra, IDA or binary ninja. Actually, together with MCPs and modern LLMs you can get a pretty good decompilation with pretty low effort.
You can also just test out transactions and see what happens, using the RPC call simulateTransaction, which also allows you to simulate a Transaction without having the correct signature.
We are currently funding a reverse engineering bounty for improving tooling and knowledge in this area. There's still over a week left to secure a slice of that $5k price! Find it here:
https://earn.superteam.fun/listing/reverse-engineering-solana/
Daily Solana Tip 100
This is going to be the last daily Solana tip.. Let me share a secret with you: The one person who has learned the most from my Solana tips is myself. I thought I already knew most of these by heart when I started writing them. But when posting a new tip, I would often double check my content and learn that I wasn't quite certain about how it actually worked. Then I looked at some code and often realized that even the official documentation had it wrong. So my last daily Solana tip is: Check the code. Don't get your absolute truths from twitter threads, outdated docs, or your cousin's mother's nephew. Read the code. Run the code. Write some code to try it out. Check it for yourself. It's the only way you can know for sure that something is the way it is. Hope you've enjoyed my 100 days of Solana tips. I will probably take some days off posting. I'm planning on posting more long form content when I'm recharged. So look out for the @accretion_xyz blog.

Accretion Labs Pte. Ltd.
65 Chulia Street, #46-00 OCBC Centre
Singapore 049513
Singapore
UEN 202502288W